
En el mundo actual, el aprendizaje automático es muy importante ya que la inteligencia artificial se considera una parte integral del mismo. El estudio de los algoritmos informáticos mediante el uso de datos es lo que hace el aprendizaje automático.
Recopilan datos, también conocidos como "datos de entrenamiento", para predecir cómo realizarán las tareas. El aprendizaje automático se utiliza en una variedad de áreas, como en medicina, filtrado de correos electrónicos, etc.
El agrupamiento y la clasificación utilizan métodos estadísticos para recopilar datos, especialmente en el campo del aprendizaje automático.
Puntos clave
- La agrupación en clústeres es una técnica utilizada para agrupar puntos de datos similares en función de sus características, mientras que la clasificación clasifica los datos en clases predefinidas en función de sus características.
- El agrupamiento es más útil cuando no hay conocimiento previo de los datos y el objetivo es descubrir patrones subyacentes. Al mismo tiempo, la clasificación es más adecuada cuando el objetivo es asignar nuevos datos a categorías preexistentes.
- Varios algoritmos de agrupamiento incluyen k-means, jerárquico y DBSCAN, mientras que varios algoritmos de clasificación incluyen árboles de decisión, regresión logística y máquinas de vectores de soporte.
Agrupación vs Clasificación
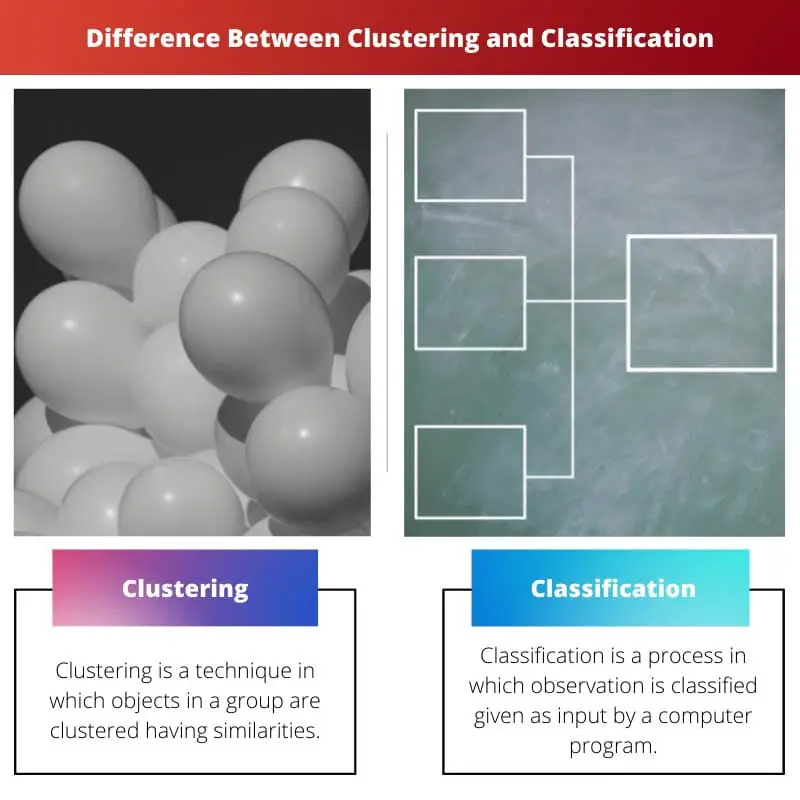
La agrupación agrupa puntos de datos en función de similitudes sin categorías predefinidas, mientras que la clasificación asigna puntos de datos a clases predeterminadas mediante el aprendizaje supervisado. La diferencia clave radica en el enfoque de aprendizaje: el agrupamiento emplea técnicas no supervisadas y la clasificación se basa en métodos supervisados.

La agrupación en clústeres también se denomina análisis de clústeres en el aprendizaje automático. Es el proceso en el que un objeto se agrupa de tal manera que los objetos dentro de los grupos tienen propiedades similares, pero cuando se compara con otro grupo, es muy diferente a él.
Esta técnica de agrupamiento se utiliza en el análisis de datos estadísticos y exploratorios en procesos como el análisis de imágenes, la compresión de datos, la recuperación de información, el reconocimiento de patrones, la bioinformática, los gráficos por computadora y el aprendizaje automático.
La clasificación también se denomina clasificación estadística en el aprendizaje automático. Es un proceso en el que los objetos se clasifican y se colocan en un conjunto de compartimentos categorizados.
La clasificación se realiza sobre observaciones cuantificables. Un algoritmo que incorpora la clasificación se conoce como clasificador. La clasificación se basa en un proceso de dos pasos: los pasos de aprendizaje y clasificación.
Tabla de comparación
| Parámetros de comparación | Clustering | Clasificación |
|---|---|---|
| Definición | El agrupamiento es una técnica en la que los objetos de un grupo se agrupan teniendo similitudes. | La clasificación es un proceso en el que la observación se clasifica dada como entrada por un programa de computadora. |
| Datos | La agrupación en clústeres no requiere datos de entrenamiento. | La clasificación requiere datos de entrenamiento. |
| Fase | Incluye etapa única, es decir, agrupación. | Incluye dos pasos: datos de entrenamiento y pruebas. |
| Etiquetado | Se trata de datos no etiquetados. | Se trata de datos etiquetados y no etiquetados en sus procesos. |
| Objetivo | Su objetivo principal es desentrañar el patrón oculto, así como las relaciones estrechas. | Su objetivo es definir el grupo al que pertenecen los objetos. |
¿Qué es la agrupación?
La agrupación en clústeres es parte del aprendizaje automático que agrupa los datos en clústeres con una gran similitud, pero diferentes clústeres pueden diferir. Es un método de aprendizaje no supervisado y se usa muy comúnmente para el análisis de datos estadísticos.
Hay diferentes tipos de algoritmos de agrupamiento como K-means, DBSCAN, Fuzzy C-means, agrupamiento jerárquico y gaussiano (EM).
La agrupación en clústeres no requiere datos de entrenamiento. En comparación con la clasificación, la agrupación en clústeres es menos compleja, ya que solo incluye la agrupación de datos. No da etiquetas a cada grupo como clasificación.
Tiene un proceso de un solo paso conocido como Agrupación. La agrupación en clústeres se puede formular como un problema de optimización de objetivos múltiples que se centra en múltiples problemas.
El agrupamiento fue creado por primera vez por Driver y Kroeber en el campo de antropología en el año 1932. Luego fue introducido a varios campos por varias personas.
Cartell usó el agrupamiento popular para la clasificación de la teoría de rasgos en la psicología de la personalidad en 1943. Se puede distinguir aproximadamente como agrupamiento duro y agrupamiento suave.
Tiene diferentes aplicaciones, como cliente segregación, análisis de redes sociales, detección de tendencias de datos dinámicos y entornos de computación en la nube.

¿Qué es la clasificación?
La clasificación se utiliza básicamente para el reconocimiento de patrones, donde el valor de salida se asigna al valor de entrada, al igual que la agrupación. La clasificación es una técnica utilizada en la minería de datos, pero también se utiliza en el aprendizaje automático.
En Machine Learning, la salida juega un papel importante y surge la necesidad de Clasificación y Regresión. Ambos son algoritmos de aprendizaje supervisado, a diferencia del agrupamiento.
Cuando la salida tiene un valor discreto, entonces se considera un problema de clasificación. Los algoritmos de clasificación ayudan a predecir la salida de datos dados cuando se les proporciona una entrada.
Puede haber varios tipos de clasificaciones como clasificación binaria, clasificación multiclase, etc.
Los diferentes tipos de clasificación también incluyen redes neuronales, clasificadores lineales: regresión logística, clasificador naïve bayesiano: bosque aleatorio, árboles de decisión, clasificación más cercana Vecinoy árboles potenciados.
Varias aplicaciones del algoritmo de clasificación incluyen reconocimiento de voz, identificación biométrica, reconocimiento de escritura a mano, detección de spam de correo electrónico, aprobación de préstamos bancarios, clasificación de documentos, etc. La clasificación requiere datos de entrenamiento y requiere datos predefinidos, a diferencia del agrupamiento. Es un proceso muy complejo. Es el resultado del aprendizaje supervisado. Se trata de datos etiquetados y no etiquetados. Implica dos procesos: entrenamiento y prueba.
Principales diferencias entre agrupamiento y clasificación
- El agrupamiento es una técnica en la que los objetos de grupo se agrupan con similitudes. Es el resultado del aprendizaje supervisado. La clasificación es un proceso en el que la observación se clasifica dada como entrada por un programa de computadora. Es el resultado de un aprendizaje no supervisado.
- La agrupación en clústeres no requiere datos de entrenamiento. La clasificación requiere datos de entrenamiento.
- El agrupamiento incluye una sola etapa, es decir, agrupamiento. La clasificación incluye dos pasos: entrenamiento y prueba.
- El agrupamiento trata con datos no etiquetados. La clasificación trata tanto con datos etiquetados como sin etiquetar en sus procesos.
- El objetivo principal de la agrupación es desentrañar el patrón oculto, así como las relaciones estrechas. El objetivo de la clasificación es definir el grupo al que pertenecen los objetos.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Última actualización: 18 de junio de 2023

Sandeep Bhandari tiene una Licenciatura en Ingeniería Informática de la Universidad de Thapar (2006). Tiene 20 años de experiencia en el campo de la tecnología. Tiene un gran interés en varios campos técnicos, incluidos los sistemas de bases de datos, las redes informáticas y la programación. Puedes leer más sobre él en su página de biografía.






Esta información es muy útil para comprender las diferencias clave entre agrupación y clasificación, así como sus aplicaciones.
¡Absolutamente! Es una excelente descripción general de las técnicas de aprendizaje automático y sus usos prácticos en diferentes campos.
La tabla de comparación es particularmente útil para comprender los parámetros de comparación entre agrupamiento y clasificación. Es claro y conciso.
Estoy de acuerdo, la comparación lado a lado facilita la comprensión de las principales diferencias entre los dos conceptos.
Aprecio que se destaquen los requisitos de datos para la agrupación y clasificación. Es un factor esencial a considerar en aplicaciones del mundo real.
La explicación detallada de la clasificación, incluidos los diferentes tipos de clasificadores, proporciona una comprensión integral de esta técnica de aprendizaje automático.
De hecho, el artículo proporciona información valiosa sobre las diversas aplicaciones de los algoritmos de clasificación y su importancia en el campo del aprendizaje automático.
La explicación detallada de la agrupación y la clasificación es reveladora, especialmente para aquellos que son nuevos en los conceptos.
No podría estar mas de acuerdo. Proporciona una base sólida para comprender los fundamentos del aprendizaje automático.
Por supuesto, la división entre enfoques de aprendizaje supervisado y no supervisado está bien articulada en este artículo.
Las explicaciones claras sobre agrupación y clasificación son muy informativas y brindan una descripción general completa de estas técnicas de aprendizaje automático.
No podría estar mas de acuerdo. El artículo ofrece un análisis bien estructurado y profundo de ambos conceptos.
La distinción entre agrupación dura y agrupación blanda es un aspecto intrigante del artículo y añade profundidad a la discusión sobre la agrupación.
Absolutamente, es una consideración importante al implementar métodos de agrupación en clústeres en diferentes contextos.
A mí también me parece fascinante. Muestra la complejidad y los matices de las técnicas de agrupación en clústeres en aplicaciones del mundo real.
Las descripciones detalladas de agrupación y clasificación, junto con sus respectivos algoritmos, ofrecen una comprensión completa de estos métodos de aprendizaje automático y su relevancia en diversas aplicaciones.
Definitivamente. El artículo transmite de manera efectiva la importancia de la agrupación y la clasificación para abordar los desafíos del análisis de datos del mundo real en diferentes dominios.
El contexto histórico proporcionado para la agrupación es interesante y añade profundidad a la discusión.
Definitivamente. Comprender los orígenes de estos conceptos ayuda a contextualizar su importancia en el análisis de datos y el aprendizaje automático modernos.
El énfasis en los enfoques de aprendizaje supervisado y la importancia del valor de salida en la clasificación está bien articulado y enriquece la comprensión de estos conceptos.
Absolutamente. Es un aspecto crucial a considerar al profundizar en la implementación práctica de algoritmos de clasificación.
Las aplicaciones mencionadas tanto para la agrupación como para la clasificación son diversas y demuestran la relevancia de estas técnicas en varios dominios.
¡Absolutamente! Los ejemplos del mundo real son cruciales para comprender el impacto de la agrupación y la clasificación en diferentes campos.
Estoy completamente de acuerdo. Es impresionante ver cómo se pueden aplicar estos métodos en escenarios prácticos, desde la segregación de clientes hasta la computación en la nube.