
No mundo de hoje, o aprendizado de máquina é muito importante, pois a inteligência artificial é vista como parte integrante dele. O estudo de algoritmos de computador usando dados é o que o aprendizado de máquina faz.
Eles coletam dados, também conhecidos como 'dados de treinamento, para prever como executarão as tarefas. O aprendizado de máquina é usado em diversas áreas, como na medicina, filtragem de e-mails, etc.
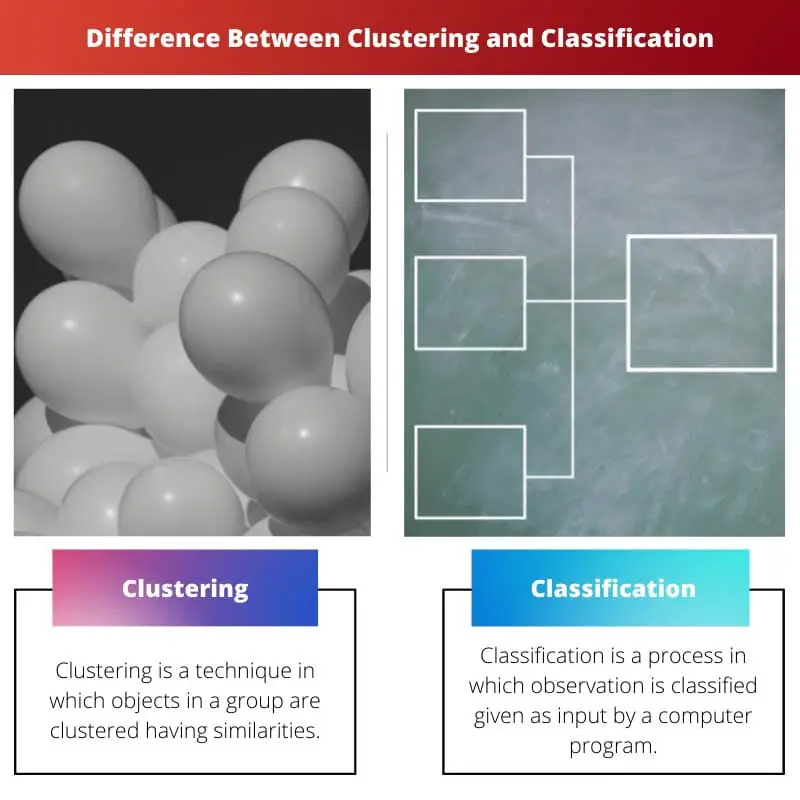
O clustering e a classificação usam métodos estatísticos para coletar dados, especialmente no campo do aprendizado de máquina.
Principais lições
- O clustering é uma técnica usada para agrupar pontos de dados semelhantes com base em suas características, enquanto a classificação classifica os dados em classes predefinidas com base em seus recursos.
- O agrupamento é mais útil quando não há conhecimento prévio dos dados e o objetivo é descobrir padrões subjacentes. Ao mesmo tempo, a classificação é mais adequada quando o objetivo é atribuir novos dados a categorias pré-existentes.
- Vários algoritmos de agrupamento incluem k-means, hierárquico e DBSCAN, enquanto vários algoritmos de classificação incluem árvores de decisão, regressão logística e máquinas de vetores de suporte.
Agrupamento x Classificação
O agrupamento agrupa pontos de dados com base em semelhanças sem categorias predefinidas, enquanto a classificação atribui pontos de dados a classes predeterminadas usando aprendizado supervisionado. A principal diferença está na abordagem de aprendizado: o agrupamento emprega técnicas não supervisionadas e a classificação depende de métodos supervisionados.

O clustering também é chamado de análise de cluster no aprendizado de máquina. É o processo no qual um objeto é agrupado de forma que os objetos dentro dos clusters tenham propriedades semelhantes, mas quando comparados a outro cluster, são muito diferentes dele.
Essa técnica de agrupamento é usada na análise estatística e exploratória de dados em processos como análise de imagens, compactação de dados, recuperação de informações, reconhecimento de padrões, bioinformática, computação gráfica e aprendizado de máquina.
A classificação também é chamada de classificação estatística no aprendizado de máquina. É um processo no qual os objetos são classificados e colocados em um conjunto de compartimentos categorizados.
A classificação é feita em observações quantificáveis. Um algoritmo que incorpora a classificação é conhecido como classificador. A classificação é baseada em um processo de duas etapas: as etapas de aprendizado e classificação.
Tabela de comparação
| Parâmetros de comparação | agrupamento | Classificação |
|---|---|---|
| Definição | Clustering é uma técnica na qual objetos em um grupo são agrupados tendo semelhanças. | A classificação é um processo no qual a observação é classificada dada como entrada por um programa de computador. |
| Data | Clustering não requer dados de treinamento. | A classificação requer dados de treinamento. |
| Fase | Inclui estágio único, ou seja, agrupamento. | Inclui duas etapas: dados de treinamento e teste. |
| Marcação | Ele lida com dados não rotulados. | Ele lida com dados rotulados e não rotulados em seus processos. |
| Objetivo | Seu principal objetivo é desvendar o padrão oculto, bem como estreitar relacionamentos. | Seu objetivo é definir o grupo ao qual os objetos pertencem. |
O que é Clusterização?
O clustering faz parte do aprendizado de máquina que agrupa os dados em clusters com alta similaridade, mas clusters diferentes podem diferir. É um método de aprendizado não supervisionado e é muito comumente usado para análise estatística de dados.
Existem diferentes tipos de algoritmos de agrupamento como K-means, DBSCAN, Fuzzy C-means, Hierarchical clustering e Gaussian (EM).
Clustering não requer dados de treinamento. Comparado à classificação, o agrupamento é menos complexo, pois inclui apenas o agrupamento de dados. Não dá rótulos a todos os grupos como classificação.
Ele tem um processo de etapa única conhecido como Agrupamento. O agrupamento pode ser formulado como um problema de otimização multiobjetivo com foco em vários problemas.
Clustering foi criado pela primeira vez por Driver e Kroeber no campo da antropologia no ano de 1932. Em seguida, foi introduzido em vários campos por várias pessoas.
Cartell usou o agrupamento popular para a classificação da teoria do traço na psicologia da personalidade em 1943. Pode ser distinguido grosseiramente como agrupamento rígido e agrupamento suave.
Possui diversas aplicações, como cliente segregação, análise de redes sociais, detecção de tendências dinâmicas de dados e ambientes de computação em nuvem.

O que é Classificação?
A classificação é basicamente usada para reconhecimento de padrões, onde o valor de saída é dado ao valor de entrada, assim como o clustering. A classificação é uma técnica usada na mineração de dados, mas também usada no aprendizado de máquina.
No Machine Learning, a saída desempenha um papel importante e surge a necessidade de Classificação e Regressão. Ambos são algoritmos de aprendizado supervisionado, ao contrário do agrupamento.
Quando a saída tem um valor discreto, então é considerado um problema de classificação. Os algoritmos de classificação ajudam a prever a saída de um determinado dado quando a entrada é fornecida a eles.
Pode haver vários tipos de classificações, como classificação binária, classificação multiclasse, etc.
Diferentes tipos de classificação também incluem Redes Neurais, Classificadores Lineares: Regressão Logística, Classificador Naïve Bayes: Floresta Aleatória, Árvores de Decisão, Vizinho, e Árvores Impulsionadas.
Várias aplicações do algoritmo de classificação incluem reconhecimento de fala, identificação biométrica, reconhecimento de manuscrito, detecção de spam por e-mail, aprovação de empréstimo bancário, classificação de documentos, etc. A classificação requer dados de treinamento e dados predefinidos, ao contrário do agrupamento. É um processo muito complexo. É resultado do aprendizado supervisionado. Ele lida com dados rotulados e não rotulados. Envolve dois processos: treinamento e teste.
Principais diferenças entre agrupamento e classificação
- Clustering é uma técnica na qual objetos de grupo são agrupados com semelhanças. É resultado do aprendizado supervisionado. A classificação é um processo no qual a observação é classificada dada como entrada por um programa de computador. É o resultado do aprendizado não supervisionado.
- Clustering não requer dados de treinamento. A classificação requer dados de treinamento.
- Clustering inclui estágio único, ou seja, agrupamento. A classificação inclui duas etapas: treinamento e teste.
- Clustering lida com dados não rotulados. A classificação lida com dados rotulados e não rotulados em seus processos.
- O principal objetivo do agrupamento é desvendar o padrão oculto, bem como estreitar os relacionamentos. O objetivo da classificação é definir o grupo ao qual os objetos pertencem.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Última atualização: 18 de junho de 2023

Sandeep Bhandari é bacharel em Engenharia de Computação pela Thapar University (2006). Possui 20 anos de experiência na área de tecnologia. Ele tem grande interesse em vários campos técnicos, incluindo sistemas de banco de dados, redes de computadores e programação. Você pode ler mais sobre ele em seu página bio.






Esta informação é muito útil para entender as principais diferenças entre clustering e classificação, bem como suas aplicações.
Absolutamente! É uma excelente visão geral das técnicas de aprendizado de máquina e seus usos práticos em diferentes campos.
A tabela de comparação é particularmente útil para compreender os parâmetros de comparação entre agrupamento e classificação. É claro e conciso.
Concordo que a comparação lado a lado facilita a compreensão das principais diferenças entre os dois conceitos.
Compreendo que os requisitos de dados para agrupamento e classificação sejam destacados. É um fator essencial a ser considerado em aplicações do mundo real.
A explicação detalhada da classificação, incluindo os diferentes tipos de classificadores, fornece uma compreensão abrangente desta técnica de aprendizado de máquina.
Na verdade, o artigo fornece informações valiosas sobre as diversas aplicações dos algoritmos de classificação e sua importância no campo do aprendizado de máquina.
A explicação detalhada de agrupamento e classificação é esclarecedora, especialmente para aqueles que são novos nos conceitos.
Eu não poderia concordar mais. Ele fornece uma base sólida para a compreensão dos fundamentos do aprendizado de máquina.
Com certeza, a divisão entre abordagens de aprendizagem não supervisionada e supervisionada está bem articulada neste artigo.
As explicações claras sobre agrupamento e classificação são altamente informativas e fornecem uma visão geral abrangente dessas técnicas de aprendizado de máquina.
Eu não poderia concordar mais. O artigo oferece uma análise bem estruturada e criteriosa de ambos os conceitos.
A distinção entre Hard Clustering e Soft Clustering é um aspecto intrigante do artigo e acrescenta profundidade à discussão sobre clustering.
Com certeza, é uma consideração importante ao implementar métodos de cluster em diferentes contextos.
Também acho fascinante. Ele mostra a complexidade e as nuances das técnicas de clustering em aplicações do mundo real.
As descrições detalhadas de clustering e classificação, juntamente com seus respectivos algoritmos, oferecem uma compreensão completa desses métodos de aprendizado de máquina e sua relevância em diversas aplicações.
Definitivamente. O artigo transmite com eficácia a importância do agrupamento e da classificação na abordagem dos desafios de análise de dados do mundo real em diferentes domínios.
O contexto histórico fornecido para o agrupamento é interessante e acrescenta profundidade à discussão.
Definitivamente. Compreender as origens desses conceitos ajuda a contextualizar seu significado na análise de dados moderna e no aprendizado de máquina.
A ênfase nas abordagens de aprendizagem supervisionada e na importância do valor do resultado na classificação é bem articulada e enriquece a compreensão destes conceitos.
Absolutamente. É um aspecto crucial a considerar ao nos aprofundarmos na implementação prática de algoritmos de classificação.
As aplicações mencionadas tanto para agrupamento como para classificação são diversas e demonstram a relevância destas técnicas em vários domínios.
Absolutamente! Os exemplos do mundo real são cruciais para compreender o impacto do agrupamento e da classificação em diferentes campos.
Eu concordo completamente. É impressionante ver como esses métodos podem ser aplicados em cenários práticos, desde a segregação de clientes até a computação em nuvem.