
V dnešním světě je strojové učení velmi důležité, protože umělá inteligence je považována za jeho nedílnou součást. Strojové učení dělá studium počítačových algoritmů pomocí dat.
Shromažďují data, známá také jako 'tréninková data, aby předpověděli, jak budou plnit úkoly. Strojové učení se používá v různých oblastech, jako je medicína, filtrování e-mailů atd.
Clustering a Classification využívají statistické metody pro sběr dat, zejména v oblasti strojového učení.
Key Takeaways
- Clustering je technika používaná k seskupování podobných datových bodů na základě jejich charakteristik, zatímco klasifikace kategorizuje data do předem definovaných tříd na základě jejich vlastností.
- Shlukování je užitečnější, když neexistují žádné předchozí znalosti o datech a cílem je objevit základní vzorce. Klasifikace je zároveň vhodnější, když je cílem přiřadit nová data již existujícím kategoriím.
- Různé shlukovací algoritmy zahrnují k-means, hierarchický a DBSCAN, zatímco různé klasifikační algoritmy zahrnují rozhodovací stromy, logistickou regresi a podpůrné vektorové stroje.
Klastrování vs klasifikace
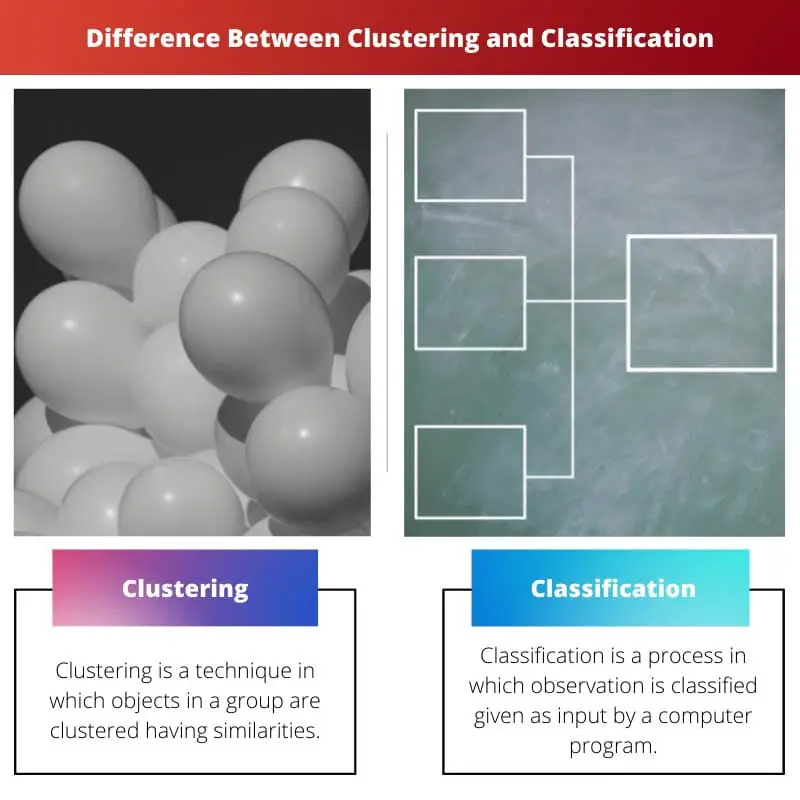
Shlukování seskupuje datové body na základě podobností bez předem definovaných kategorií, zatímco klasifikace přiřazuje datové body předem určeným třídám pomocí učení pod dohledem. Klíčový rozdíl spočívá v přístupu k učení: shlukování využívá techniky bez dohledu a klasifikace se opírá o metody pod dohledem.

Shlukování se ve strojovém učení také nazývá shluková analýza. Je to proces, při kterém je objekt seskupován tak, že objekty uvnitř shluků mají podobné vlastnosti, ale ve srovnání s jiným shlukem se mu velmi nepodobají.
Tato technika shlukování se používá ve statistické a explorativní analýze dat v procesech, jako je analýza obrazu, komprese dat, získávání informací, rozpoznávání vzorů, bioinformatika, počítačová grafika a strojové učení.
Klasifikace se ve strojovém učení také nazývá statistická klasifikace. Je to proces, ve kterém jsou objekty klasifikovány a umístěny do sady kategorizovaných oddílů.
Klasifikace se provádí na základě kvantifikovatelných pozorování. Algoritmus, který zahrnuje klasifikaci, je známý jako klasifikátor. Klasifikace je založena na dvoustupňovém procesu: učení a klasifikaci.
Srovnávací tabulka
| Parametry srovnání | Clustering | Klasifikace |
|---|---|---|
| Definice | Shlukování je technika, při které se objekty ve skupině shlukují a mají podobnosti. | Klasifikace je proces, ve kterém je pozorování klasifikováno jako vstup zadaný počítačovým programem. |
| Data | Clustering nevyžaduje trénovací data. | Klasifikace vyžaduje tréninková data. |
| Fáze | Zahrnuje jednostupňové, tj. seskupování. | Zahrnuje dva kroky: tréninková data a testování. |
| Označování | Zabývá se neoznačenými daty. | Ve svých procesech se zabývá jak označenými, tak neoznačenými daty. |
| Objektivní | Jeho hlavním cílem je odhalit skrytý vzorec i úzké vztahy. | Jeho cílem je definovat skupinu, do které objekty patří. |
Co je Clustering?
Shlukování je součástí strojového učení, které seskupuje data do shluků s vysokou podobností, ale různé shluky se mohou lišit. Je to metoda učení bez dozoru a velmi běžně se používá pro statistickou analýzu dat.
Existují různé typy shlukovacích algoritmů jako K-means, DBSCAN, Fuzzy C-means, Hierarchical clustering a Gaussian (EM).
Clustering nevyžaduje trénovací data. Ve srovnání s klasifikací je shlukování méně složité, protože zahrnuje pouze seskupování dat. Nedává označení pro každou skupinu, jako je klasifikace.
Má jednokrokový proces známý jako seskupování. Clustering lze formulovat jako multi-cílový optimalizační problém se zaměřením na více problémů.
Clustering poprvé vytvořili Driver a Kroeber v oboru antropologie v roce 1932. Poté byl uveden do různých oblastí různými osobami.
Cartell použil populární shlukování pro klasifikaci teorie vlastností v psychologii osobnosti v roce 1943. Lze jej zhruba rozlišit jako tvrdé shlukování a měkké shlukování.
Má různé aplikace, jako např zákazník segregace, analýza sociálních sítí, zjišťování trendů dynamických dat a prostředí cloud computingu.

Co je klasifikace?
Klasifikace se v zásadě používá pro rozpoznávání vzorů, kdy výstupní hodnota je dána vstupní hodnotě, stejně jako shlukování. Klasifikace je technika používaná při dolování dat, ale také používaná ve strojovém učení.
Ve strojovém učení hraje výstup důležitou roli a přichází potřeba klasifikace a regrese. Oba jsou na rozdíl od shlukování algoritmy učení pod dohledem.
Když má výstup diskrétní hodnotu, považuje se to za klasifikační problém. Klasifikační algoritmy pomáhají předvídat výstup daných dat, když je jim poskytnut vstup.
Mohou existovat různé typy klasifikací, jako je binární klasifikace, klasifikace více tříd atd.
Různé typy klasifikace také zahrnují neuronové sítě, lineární klasifikátory: logistická regrese, naivní Bayesův klasifikátor: náhodný les, rozhodovací stromy, nejbližší Souseda Boosted Trees.
Různé aplikace klasifikačního algoritmu zahrnují rozpoznávání řeči, biometrickou identifikaci, rozpoznávání rukopisu, detekci spamu v e-mailu, schvalování bankovních půjček, klasifikaci dokumentů atd. Klasifikace vyžaduje trénovací data a na rozdíl od shlukování vyžaduje předdefinovaná data. Je to velmi složitý proces. Je to výsledek učení pod dohledem. Zabývá se jak označenými, tak neoznačenými daty. Zahrnuje dva procesy: školení a testování.
Hlavní rozdíly mezi shlukováním a klasifikací
- Shlukování je technika, při které se skupinové objekty shlukují s podobnostmi. Je to výsledek učení pod dohledem. Klasifikace je proces, ve kterém je pozorování klasifikováno jako vstup zadaný počítačovým programem. Je to výsledek učení bez dozoru.
- Clustering nevyžaduje trénovací data. Klasifikace vyžaduje tréninková data.
- Shlukování zahrnuje jednostupňové, tj. seskupování. Klasifikace zahrnuje dva kroky: školení a testování.
- Clustering se zabývá neoznačenými daty. Klasifikace se ve svých procesech zabývá jak označenými, tak neoznačenými daty.
- Hlavním cílem shlukování je odhalit skrytý vzorec i úzké vztahy. Cílem klasifikace je definovat skupinu, do které objekty patří.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Poslední aktualizace: 18. června 2023

Sandeep Bhandari získal bakalářský titul v oboru počítačů na Thapar University (2006). Má 20 let zkušeností v oblasti technologií. Má velký zájem o různé technické obory, včetně databázových systémů, počítačových sítí a programování. Více si o něm můžete přečíst na jeho bio stránka.






Tyto informace jsou velmi užitečné pro pochopení klíčových rozdílů mezi shlukováním a klasifikací a také jejich aplikací.
Absolutně! Je to skvělý přehled technik strojového učení a jejich praktického využití v různých oborech.
Srovnávací tabulka je zvláště užitečná pro pochopení parametrů srovnání mezi shlukováním a klasifikací. Je to jasné a stručné.
Souhlasím, srovnání vedle sebe usnadňuje pochopení hlavních rozdílů mezi těmito dvěma pojmy.
Oceňuji, že jsou zvýrazněny požadavky na data pro shlukování a klasifikaci. Je to zásadní faktor, který je třeba vzít v úvahu v aplikacích v reálném světě.
Podrobné vysvětlení klasifikace, včetně různých typů klasifikátorů, poskytuje komplexní pochopení této techniky strojového učení.
Článek skutečně poskytuje cenné poznatky o různých aplikacích klasifikačních algoritmů a jejich významu v oblasti strojového učení.
Podrobné vysvětlení shlukování a klasifikace je užitečné, zejména pro ty, kteří s těmito pojmy začínají.
Nemohl jsem více souhlasit. Poskytuje pevný základ pro pochopení základů strojového učení.
V tomto článku je rozhodně dobře vyjádřeno rozdělení mezi přístupy k učení bez dozoru a pod dohledem.
Jasná vysvětlení shlukování a klasifikace jsou vysoce informativní a poskytují komplexní přehled těchto technik strojového učení.
Nemohl jsem více souhlasit. Článek nabízí dobře strukturovanou a zasvěcenou analýzu obou pojmů.
Rozdíl mezi tvrdým shlukováním a měkkým shlukováním je zajímavým aspektem článku a dodává diskuzi o shlukování hloubku.
Rozhodně je to důležitý faktor při implementaci metod shlukování v různých kontextech.
Připadá mi to také fascinující. Ukazuje složitost a nuance technik shlukování v aplikacích v reálném světě.
Podrobné popisy shlukování a klasifikace spolu s jejich příslušnými algoritmy nabízejí ucelené pochopení těchto metod strojového učení a jejich význam v různých aplikacích.
Rozhodně. Článek účinně vyjadřuje význam shlukování a klasifikace při řešení problémů analýzy reálných dat napříč různými doménami.
Historický kontext poskytnutý pro shlukování je zajímavý a dodává diskusi na hloubce.
Rozhodně. Pochopení původu těchto konceptů pomáhá uvést do kontextu jejich význam v moderní analýze dat a strojovém učení.
Důraz na přístupy k učení pod dohledem a význam výstupní hodnoty v klasifikaci je dobře formulován a obohacuje pochopení těchto pojmů.
Absolutně. Je to zásadní aspekt, který je třeba vzít v úvahu při praktické implementaci klasifikačních algoritmů.
Zmíněné aplikace pro shlukování i klasifikaci jsou různorodé a demonstrují význam těchto technik v různých doménách.
Absolutně! Příklady z reálného světa jsou zásadní pro pochopení dopadu shlukování a klasifikace v různých oblastech.
Naprosto souhlasím. Je působivé vidět, jak lze tyto metody aplikovat v praktických scénářích, od segregace zákazníků po cloud computing.