
今日の世界では、人工知能がその不可欠な部分と見なされているため、機械学習は非常に重要です。 データを使用してコンピューター アルゴリズムを研究するのは、機械学習です。
彼らは、タスクをどのように実行するかを予測するために、「トレーニング データ」とも呼ばれるデータを収集します。 機械学習は、医療やメールのフィルタリングなど、さまざまな分野で使用されています。
クラスタリングと分類では、特に機械学習の分野でデータを収集するために統計的手法が使用されます。
主要な取り組み
- クラスタリングは、特徴に基づいて同様のデータ ポイントをグループ化するために使用される手法であり、分類は、データをその特徴に基づいて事前定義されたクラスに分類します。
- クラスタリングは、データに関する事前知識がなく、その目的が根底にあるパターンを発見する場合に、より役立ちます。 同時に、新しいデータを既存のカテゴリに割り当てることが目標である場合は、分類の方が適しています。
- さまざまなクラスタリング アルゴリズムには、k-means、階層、および DBSCAN が含まれ、さまざまな分類アルゴリズムには、デシジョン ツリー、ロジスティック回帰、およびサポート ベクター マシンが含まれます。
クラスタリングと分類
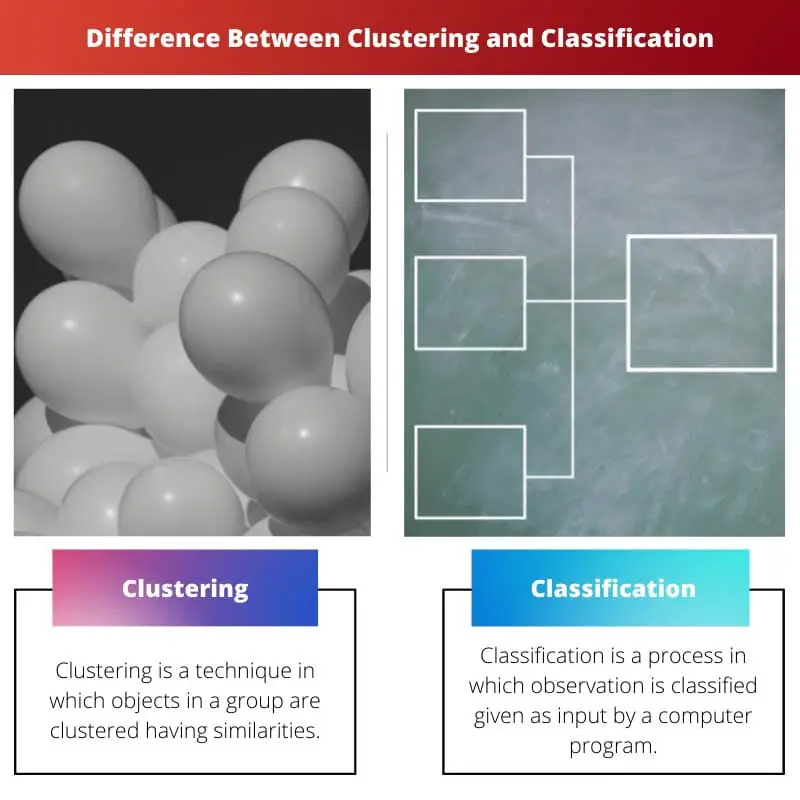
クラスタリングでは、事前に定義されたカテゴリを使用せずに、類似性に基づいてデータ ポイントをグループ化しますが、分類では、教師あり学習を使用してデータ ポイントを所定のクラスに割り当てます。 主な違いは学習アプローチにあります。クラスタリングは教師なし手法を採用し、分類は教師あり手法に依存しています。

クラスタリングは、機械学習ではクラスター分析とも呼ばれます。 これは、クラスター内のオブジェクトが同様のプロパティを持つようにオブジェクトをグループ化するプロセスですが、別のクラスターと比較すると、そのオブジェクトは非常に似ていません。
このクラスタリング手法は、画像分析、データ圧縮、情報検索、パターン認識、バイオインフォマティクス、コンピューター グラフィックス、機械学習などのプロセスにおける統計的および探索的データ分析に使用されます。
分類は、機械学習では統計的分類とも呼ばれます。 これは、オブジェクトが分類され、分類された一連のコンパートメントに入れられるプロセスです。
分類は定量化可能な観察に基づいて行われます。 分類を組み込んだアルゴリズムは分類子として知られています。 分類は、学習ステップと分類ステップという XNUMX 段階のプロセスに基づいています。
比較表
| 比較のパラメータ | クラスタリング | Classification |
|---|---|---|
| 定義 | クラスタリングは、グループ内のオブジェクトが類似性を持ってクラスター化される手法です。 | 分類とは、コンピュータ プログラムによって入力として与えられた観察を分類するプロセスです。 |
| 且つ | クラスタリングにはトレーニング データは必要ありません。 | 分類にはトレーニング データが必要です。 |
| 相 | これには、単一段階、つまりグループ化が含まれます。 | これには、トレーニング データとテストの XNUMX つのステップが含まれます。 |
| ラベリング | ラベルのないデータを扱います。 | そのプロセスでは、ラベル付けされたデータとラベル付けされていないデータの両方を処理します。 |
| DevOps Tools Engineer試験のObjective | その主な目的は、隠されたパターンと狭い関係を解明することです。 | その目的は、オブジェクトが属するグループを定義することです。 |
クラスタリングとは
クラスタリングは、データを類似性の高いクラスターにグループ化する機械学習の一部ですが、クラスターごとに異なる場合があります。 これは教師なし学習の方法であり、統計データ分析に非常に一般的に使用されます。
K-means、DBSCAN、Fuzzy C-means、階層クラスタリング、Gaussian (EM) など、さまざまな種類のクラスタリング アルゴリズムがあります。
クラスタリングにはトレーニング データは必要ありません。 分類と比較すると、クラスタリングにはデータのグループ化のみが含まれるため、それほど複雑ではありません。 分類のようにすべてのグループにラベルを付けるわけではありません。
これには、グループ化と呼ばれる単一ステップのプロセスがあります。 クラスタリングは、複数の問題に焦点を当てた多目的最適化問題として定式化できます。
クラスタリングは、Driver と Kroeber によって、 人類学 その後、さまざまな人物によってさまざまな分野に導入されました。
カルテルは、1943 年に性格心理学における特性理論の分類に一般的なクラスタリングを使用しました。これはハード クラスタリングとソフト クラスタリングとして大まかに区別できます。
さまざまな用途があります。 顧客 分離、ソーシャル ネットワーク分析、動的データ トレンドの検出、およびクラウド コンピューティング環境。

分類とは
分類は基本的にパターン認識に使用され、クラスタリングと同様に出力値が入力値に与えられます。 分類はデータマイニングで使用される手法ですが、機械学習でも使用されます。
機械学習では出力が重要な役割を果たし、分類と回帰が必要になります。 クラスタリングとは異なり、どちらも教師あり学習アルゴリズムです。
出力に離散値がある場合、それは分類問題と見なされます。 分類アルゴリズムは、入力が与えられたときに特定のデータの出力を予測するのに役立ちます。
分類には、二項分類、多クラス分類など、さまざまなタイプがあります。
さまざまなタイプの分類には、ニューラル ネットワーク、線形分類子: ロジスティック回帰、単純ベイズ分類子: ランダム フォレスト、デシジョン ツリー、ニアレストも含まれます。 隣人、ブーストツリー。
分類アルゴリズムのさまざまなアプリケーションには、音声認識、生体認証識別、手書き認識、電子メール スパム検出、銀行ローンの承認、文書分類などが含まれます。分類にはトレーニング データが必要で、クラスタリングとは異なり、事前定義されたデータが必要です。 それは非常に複雑なプロセスです。 それは教師あり学習の結果です。 ラベル付きデータとラベルなしデータの両方を扱います。 これには、トレーニングとテストという XNUMX つのプロセスが含まれます。
クラスタリングと分類の主な違い
- クラスタリングは、グループ オブジェクトを類似性を持ってクラスタリングする手法です。 それは教師あり学習の結果です。 分類は、コンピューター プログラムによる入力として与えられた観察を分類するプロセスです。 それは教師なし学習の結果です。
- クラスタリングにはトレーニング データは必要ありません。 分類にはトレーニング データが必要です。
- クラスタリングには、単一段階、つまりグループ化が含まれます。 分類には、トレーニングとテストの XNUMX つのステップが含まれます。
- クラスタリングはラベルのないデータを扱います。 分類では、そのプロセスでラベル付きデータとラベルなしデータの両方が処理されます。
- クラスタリングの主な目的は、隠されたパターンと狭い関係を解明することです。 分類の目的は、オブジェクトが属するグループを定義することです。
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
最終更新日 : 18 年 2023 月 XNUMX 日

Sandeep Bhandari は、Thapar University (2006) でコンピューター工学の学士号を取得しています。 彼はテクノロジー分野で 20 年の経験があります。 彼は、データベース システム、コンピュータ ネットワーク、プログラミングなど、さまざまな技術分野に強い関心を持っています。 彼の詳細については、彼のウェブサイトで読むことができます バイオページ.






この情報は、クラスタリングと分類の主な違いとその応用を理解するのに非常に役立ちます。
絶対に!これは、機械学習技術とさまざまな分野での実際の使用法についての優れた概要です。
比較表は、クラスタリングと分類の比較パラメータを理解するのに特に役立ちます。明確かつ簡潔です。
私も同感です。並べて比較すると、2 つの概念の主な違いが理解しやすくなります。
クラスタリングと分類のデータ要件が強調されていることに感謝します。これは、実際のアプリケーションでは考慮すべき重要な要素です。
さまざまな種類の分類器を含む分類の詳細な説明により、この機械学習技術を包括的に理解できます。
実際、この記事は、分類アルゴリズムのさまざまな応用と機械学習の分野におけるその重要性について貴重な洞察を提供します。
クラスタリングと分類の詳細な説明は、特にこの概念を初めて使用する人にとって、洞察力に富みます。
私はこれ以上同意できませんでした。機械学習の基礎を理解するための強力な基盤を提供します。
確かに、教師なし学習アプローチと教師あり学習アプローチの区別は、この記事で明確に説明されています。
クラスタリングと分類の明確な説明は非常に有益であり、これらの機械学習技術の包括的な概要を提供します。
私はこれ以上同意できませんでした。この記事では、両方の概念について、よく構造化された洞察に富んだ分析が提供されています。
ハード クラスタリングとソフト クラスタリングの違いは、この記事の興味深い側面であり、クラスタリングの議論に深みを与えます。
確かに、さまざまなコンテキストでクラスタリング手法を実装する場合、これは重要な考慮事項です。
私もそれが魅力的だと思います。これは、現実世界のアプリケーションにおけるクラスタリング技術の複雑さと微妙な違いを示しています。
クラスタリングと分類の詳細な説明とそれぞれのアルゴリズムは、これらの機械学習手法とさまざまなアプリケーションにおけるそれらの関連性についての包括的な理解を提供します。
絶対に。この記事は、さまざまなドメインにわたる現実世界のデータ分析の課題に対処する際のクラスタリングと分類の重要性を効果的に伝えています。
クラスタリングに関して提供される歴史的背景は興味深いものであり、議論に深みを与えます。
絶対に。これらの概念の起源を理解することは、現代のデータ分析と機械学習におけるそれらの重要性を文脈で理解するのに役立ちます。
教師あり学習アプローチと分類における出力値の重要性の強調が明確に表現されており、これらの概念の理解が深まります。
絶対に。これは、分類アルゴリズムの実際の実装を詳しく検討する際に考慮すべき重要な側面です。
クラスタリングと分類の両方について言及されているアプリケーションは多様であり、さまざまなドメインにわたるこれらの技術の関連性を示しています。
絶対に!実際の例は、さまざまな分野におけるクラスタリングと分類の影響を理解するために非常に重要です。
同意します。これらの手法が顧客の分離からクラウド コンピューティングに至るまで、実際のシナリオにどのように適用できるかを見るのは印象的です。