
在当今世界,机器学习非常重要,因为人工智能被视为其中不可或缺的一部分。 通过使用数据来研究计算机算法是机器学习所做的。
他们收集数据,也称为“训练数据”,以预测他们将如何执行任务。 机器学习用于各种领域,例如医学、电子邮件过滤等。
聚类和分类使用统计方法来收集数据,尤其是在机器学习领域。
关键精华
- 聚类是一种用于根据相似数据点的特征对它们进行分组的技术,而分类则根据它们的特征将数据分类到预定义的类中。
- 当没有数据的先验知识时,聚类更有用,目的是发现潜在的模式。 同时,当目标是将新数据分配给预先存在的类别时,分类更合适。
- 各种聚类算法包括 k-means、分层和 DBSCAN,而各种分类算法包括决策树、逻辑回归和支持向量机。
聚类与分类
聚类根据没有预定义类别的相似性对数据点进行分组,而分类使用监督学习将数据点分配给预定的类。 关键区别在于学习方法:聚类采用无监督技术,而分类依赖于监督方法。

聚类在机器学习中也称为聚类分析。 这是一个对象以这样的方式分组的过程:簇内的对象具有相似的属性,但与另一个簇相比时,它却非常不相似。
这种聚类技术用于图像分析、数据压缩、信息检索、模式识别、生物信息学、计算机图形学和机器学习等过程中的统计和探索性数据分析。
分类在机器学习中也称为统计分类。 这是将对象分类并放入一组分类隔间的过程。
分类是根据可量化的观察结果进行的。 包含分类的算法称为分类器。 分类基于两步过程:学习和分类步骤。
对比表
| 比较参数 | 聚类 | 分类 |
|---|---|---|
| 定义 | 聚类是一种将一组中的对象聚类为具有相似性的技术。 | 分类是将观察结果分类为计算机程序输入的过程。 |
| 时间 | 聚类不需要训练数据。 | 分类需要训练数据。 |
| 相 | 它包括单阶段,即分组。 | 它包括两步:训练数据和测试。 |
| 标签 | 它处理未标记的数据。 | 它在其过程中处理标记和未标记的数据。 |
| 目的 | 它的主要目标是揭开隐藏的模式和狭窄的关系。 | 它的目标是定义对象所属的组。 |
什么是聚类?
聚类是机器学习的一部分,它将数据分组到具有高相似性的集群中,但不同的集群可能不同。 它是一种无监督学习方法,非常常用于统计数据分析。
有不同类型的聚类算法,如 K 均值、DBSCAN、模糊 C 均值、层次聚类和高斯 (EM)。
聚类不需要训练数据。 与分类相比,聚类不那么复杂,因为它只包括数据分组。 它不会像分类那样给每个组都贴上标签。
它有一个称为分组的单步过程。 聚类可以表述为关注多个问题的多目标优化问题。
聚类最早是由 Driver 和 Kroeber 在 人类学 1932年,由不同的人介绍到各个领域。
Cartell于1943年将流行的聚类用于人格心理学中的特质理论分类。大致可以分为硬聚类和软聚类。
它有不同的应用,例如 顾客 隔离、社交网络分析、检测动态数据趋势和云计算环境。

什么是分类?
分类基本上用于模式识别,其中将输出值赋予输入值,就像聚类一样。 分类是一种用于数据挖掘的技术,也用于机器学习。
在机器学习中,输出起着重要作用,因此需要分类和回归。 与聚类不同,两者都是监督学习算法。
当输出具有离散值时,则将其视为分类问题。 分类算法有助于在向其提供输入时预测给定数据的输出。
可以有多种类型的分类,如二元分类、多类分类等。
不同类型的分类还包括神经网络、线性分类器:逻辑回归、朴素贝叶斯分类器:随机森林、决策树、最近 邻居和增强树。
分类算法的各种应用包括语音识别、生物特征识别、手写识别、垃圾邮件检测、银行贷款审批、文档分类等。分类需要训练数据,并且与聚类不同,它需要预定义的数据。 这是一个非常复杂的过程。 这是监督学习的结果。 它处理标记和未标记的数据。 它涉及两个过程:训练和测试。
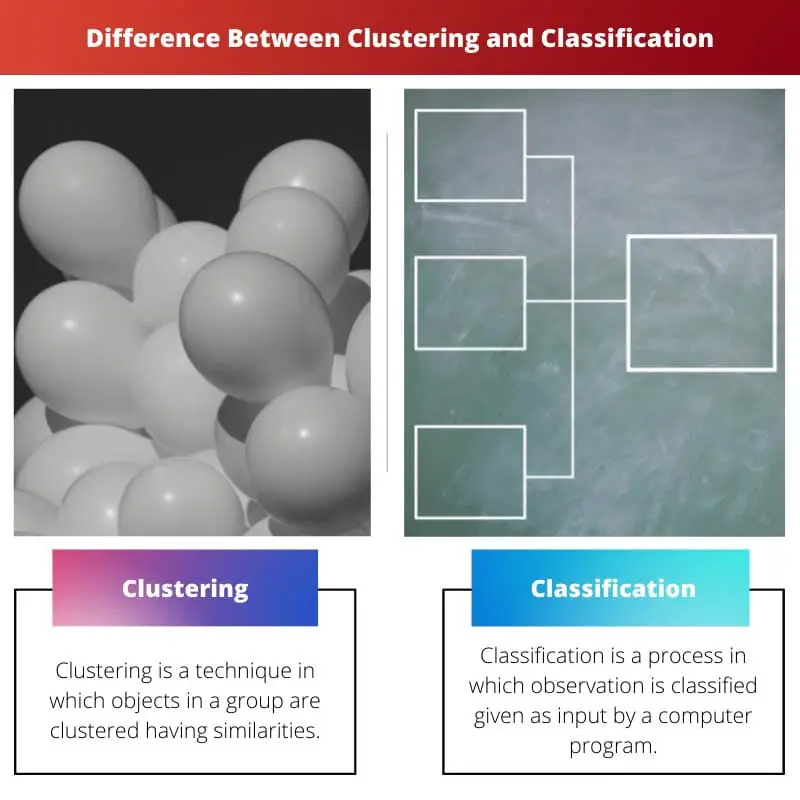
聚类和分类之间的主要区别
- 聚类是一种将具有相似性的组对象聚类的技术。 这是监督学习的结果。 分类是将观察结果分类为计算机程序输入的过程。 这是无监督学习的结果。
- 聚类不需要训练数据。 分类需要训练数据。
- 聚类包括单阶段,即分组。 分类包括两步:训练和测试。
- 聚类处理未标记的数据。 分类在其过程中处理标记和未标记的数据。
- 聚类的主要目标是揭示隐藏的模式以及狭窄的关系。 分类的目标是定义对象所属的组。
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
最后更新时间:18 年 2023 月 XNUMX 日

Sandeep Bhandari 拥有塔帕尔大学计算机工程学士学位(2006 年)。 他在技术领域拥有 20 年的经验。 他对各种技术领域都有浓厚的兴趣,包括数据库系统、计算机网络和编程。 你可以在他的网站上阅读更多关于他的信息 生物页面.






这些信息对于理解聚类和分类之间的主要区别及其应用非常有用。
绝对地!它很好地概述了机器学习技术及其在不同领域的实际用途。
比较表对于理解聚类和分类之间的比较参数特别有帮助。它清晰简洁。
我同意,并排比较可以很容易地理解两个概念之间的主要区别。
我很欣赏强调了聚类和分类的数据要求。这是在实际应用中需要考虑的重要因素。
分类的详细解释,包括不同类型的分类器,提供了对这种机器学习技术的全面理解。
事实上,本文对分类算法的各种应用及其在机器学习领域的重要性提供了宝贵的见解。
聚类和分类的详细解释很有见地,特别是对于那些刚接触这些概念的人来说。
我完全同意。它为理解机器学习的基础知识提供了坚实的基础。
当然,本文很好地阐述了无监督学习方法和监督学习方法之间的区别。
对聚类和分类的清晰解释信息量很大,并提供了这些机器学习技术的全面概述。
我完全同意。本文对这两个概念进行了结构良好且富有洞察力的分析。
硬聚类和软聚类之间的区别是本文的一个有趣的方面,并且增加了聚类讨论的深度。
当然,在不同的环境中实现聚类方法时,这是一个重要的考虑因素。
我也觉得它很有趣。它展示了实际应用中聚类技术的复杂性和细微差别。
聚类和分类的详细描述,以及它们各自的算法,提供了对这些机器学习方法及其在各种应用中的相关性的全面理解。
确实。本文有效地传达了聚类和分类在解决不同领域的现实数据分析挑战方面的重要性。
为聚类提供的历史背景很有趣,并且增加了讨论的深度。
确实。了解这些概念的起源有助于了解它们在现代数据分析和机器学习中的重要性。
对监督学习方法的强调以及分类中输出值的重要性得到了很好的阐述,并丰富了对这些概念的理解。
绝对地。在深入研究分类算法的实际实现时,这是需要考虑的一个重要方面。
提到的聚类和分类应用是多种多样的,并展示了这些技术在各个领域的相关性。
绝对地!现实世界的例子对于理解聚类和分类在不同领域的影响至关重要。
我完全同意。看到这些方法如何应用于从客户隔离到云计算的实际场景中,令人印象深刻。