
Dans le monde d'aujourd'hui, l'apprentissage automatique est très important car l'intelligence artificielle en est considérée comme une partie intégrante. L'étude des algorithmes informatiques à l'aide de données est ce que fait l'apprentissage automatique.
Ils collectent des données, également appelées «données d'entraînement», pour prédire comment ils exécuteront les tâches. L'apprentissage automatique est utilisé dans divers domaines, tels que la médecine, le filtrage des e-mails, etc.
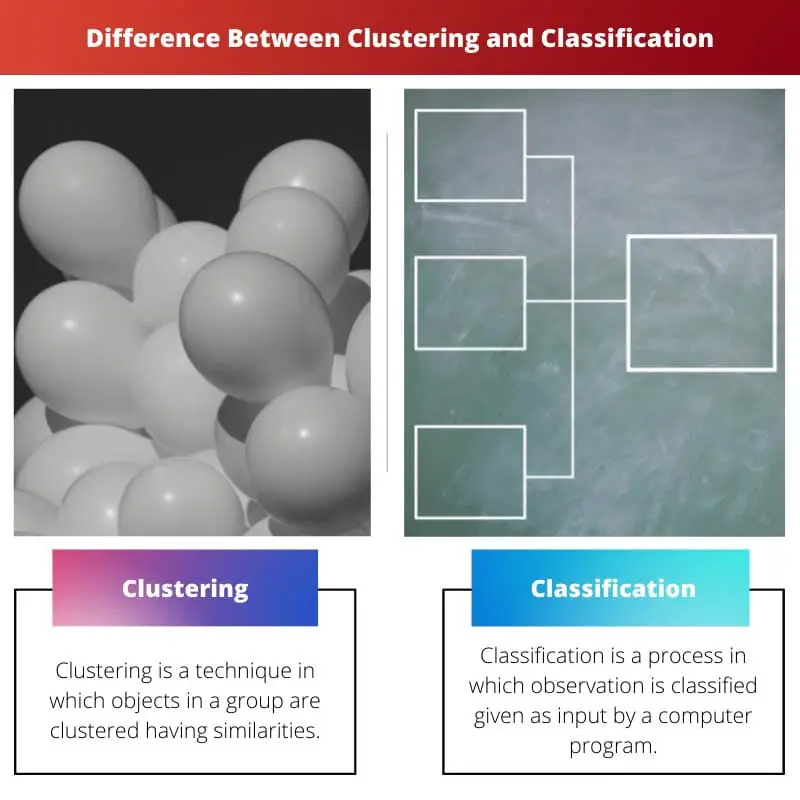
Le clustering et la classification utilisent des méthodes statistiques pour collecter des données, en particulier dans le domaine de l'apprentissage automatique.
Faits marquants
- Le clustering est une technique utilisée pour regrouper des points de données similaires en fonction de leurs caractéristiques, tandis que la classification catégorise les données en classes prédéfinies en fonction de leurs caractéristiques.
- Le regroupement est plus utile lorsqu'il n'y a aucune connaissance préalable des données et que l'objectif est de découvrir des modèles sous-jacents. Dans le même temps, la classification est plus appropriée lorsque l'objectif est d'affecter de nouvelles données à des catégories préexistantes.
- Divers algorithmes de clustering incluent k-means, hiérarchique et DBSCAN, tandis que divers algorithmes de classification incluent des arbres de décision, une régression logistique et des machines à vecteurs de support.
Regroupement vs Classification
Le regroupement regroupe les points de données en fonction de similitudes sans catégories prédéfinies, tandis que la classification attribue des points de données à des classes prédéterminées à l'aide d'un apprentissage supervisé. La principale différence réside dans l'approche d'apprentissage : le regroupement utilise des techniques non supervisées et la classification repose sur des méthodes supervisées.

Le clustering est également appelé analyse de cluster dans l'apprentissage automatique. C'est le processus dans lequel un objet est regroupé de telle manière que les objets à l'intérieur des clusters ont des propriétés similaires, mais lorsqu'ils sont comparés à un autre cluster, il est très différent de celui-ci.
Cette technique de regroupement est utilisée dans l'analyse de données statistiques et exploratoires dans des processus tels que l'analyse d'images, la compression de données, la récupération d'informations, la reconnaissance de formes, la bioinformatique, l'infographie et l'apprentissage automatique.
La classification est également appelée classification statistique dans l'apprentissage automatique. C'est un processus dans lequel les objets sont classés et placés dans un ensemble de compartiments catégorisés.
La classification se fait sur des observations quantifiables. Un algorithme qui intègre la classification est appelé classificateur. La classification est basée sur un processus en deux étapes : les étapes d'apprentissage et de classification.
Tableau de comparaison
| Paramètres de comparaison | regroupement | Classification |
|---|---|---|
| Définition | Le clustering est une technique dans laquelle les objets d'un groupe sont regroupés en ayant des similitudes. | La classification est un processus dans lequel l'observation est classée donnée comme entrée par un programme informatique. |
| Données | Le clustering ne nécessite pas de données d'apprentissage. | La classification nécessite des données de formation. |
| phase | Il comprend une seule étape, c'est-à-dire un regroupement. | Il comprend deux étapes : les données d'entraînement et les tests. |
| Étiquetage | Il traite des données non étiquetées. | Il traite à la fois les données étiquetées et non étiquetées dans ses processus. |
| Objectif | Son objectif principal est de démêler le modèle caché ainsi que les relations étroites. | Son objectif est de définir le groupe auquel appartiennent les objets. |
Qu'est-ce que le regroupement?
Le clustering fait partie de l'apprentissage automatique qui regroupe les données en clusters avec une grande similarité, mais différents clusters peuvent différer. C'est une méthode d'apprentissage non supervisé et elle est très couramment utilisée pour l'analyse de données statistiques.
Il existe différents types d'algorithmes de clustering tels que K-means, DBSCAN, Fuzzy C-means, Hierarchical clustering et Gaussian (EM).
Le clustering ne nécessite pas de données d'apprentissage. Comparé à la classification, le clustering est moins complexe car il ne comprend que le regroupement de données. Il ne donne pas d'étiquettes à chaque groupe comme la classification.
Il a un processus en une seule étape connu sous le nom de groupement. Le clustering peut être formulé comme un problème d'optimisation multi-objectifs se concentrant sur plusieurs problèmes.
Le clustering a d'abord été créé par Driver et Kroeber dans le domaine de anthropologie en 1932. Ensuite, il a été introduit dans les différents domaines par différentes personnes.
Cartell a utilisé le regroupement populaire pour la classification de la théorie des traits en psychologie de la personnalité en 1943. Il peut être grossièrement distingué comme regroupement dur et regroupement souple.
Il a différentes applications, telles que des clients la ségrégation, l'analyse des réseaux sociaux, la détection des tendances dynamiques des données et les environnements de cloud computing.

Qu'est-ce que le classement ?
La classification est essentiellement utilisée pour la reconnaissance de formes, où la valeur de sortie est donnée à la valeur d'entrée, tout comme le clustering. La classification est une technique utilisée dans l'exploration de données mais également utilisée dans l'apprentissage automatique.
Dans l'apprentissage automatique, la sortie joue un rôle important, d'où le besoin de classification et de régression. Les deux sont des algorithmes d'apprentissage supervisé, contrairement au clustering.
Lorsque la sortie a une valeur discrète, elle est alors considérée comme un problème de classification. Les algorithmes de classification aident à prédire la sortie de données données lorsqu'une entrée leur est fournie.
Il peut y avoir différents types de classifications comme la classification binaire, la classification multi-classes, etc.
Différents types de classification incluent également les réseaux de neurones, les classificateurs linéaires : régression logistique, le classificateur bayésien naïf : forêt aléatoire, les arbres de décision, le plus proche Voisin, et arbres boostés.
Diverses applications de l'algorithme de classification comprennent la reconnaissance vocale, l'identification biométrique, la reconnaissance de l'écriture manuscrite, la détection de spam par e-mail, l'approbation de prêt bancaire, la classification de documents, etc. La classification nécessite des données de formation et des données prédéfinies, contrairement au clustering. C'est un processus très complexe. C'est le résultat d'un apprentissage supervisé. Il traite à la fois des données étiquetées et non étiquetées. Il implique deux processus : la formation et les tests.
Différences principales entre le clustering et la classification
- Le clustering est une technique dans laquelle les objets de groupe sont regroupés avec des similitudes. C'est le résultat d'un apprentissage supervisé. La classification est un processus dans lequel l'observation est classée donnée comme entrée par un programme informatique. C'est le résultat d'un apprentissage non supervisé.
- Le clustering ne nécessite pas de données d'entraînement. La classification nécessite des données de formation.
- Le regroupement comprend une seule étape, c'est-à-dire le regroupement. La classification comprend deux étapes : la formation et les tests.
- Le clustering traite des données non étiquetées. La classification traite à la fois des données étiquetées et non étiquetées dans ses processus.
- L'objectif principal du clustering est de démêler le modèle caché ainsi que les relations étroites. L'objectif de la classification est de définir le groupe auquel appartiennent les objets.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Dernière mise à jour : 18 juin 2023

Sandeep Bhandari est titulaire d'un baccalauréat en génie informatique de l'Université Thapar (2006). Il a 20 ans d'expérience dans le domaine de la technologie. Il s'intéresse vivement à divers domaines techniques, notamment les systèmes de bases de données, les réseaux informatiques et la programmation. Vous pouvez en savoir plus sur lui sur son page bio.






Ces informations sont très utiles pour comprendre les principales différences entre le clustering et la classification, ainsi que leurs applications.
Absolument! C'est un excellent aperçu des techniques d'apprentissage automatique et de leurs utilisations pratiques dans différents domaines.
Le tableau de comparaison est particulièrement utile pour comprendre les paramètres de comparaison entre le clustering et la classification. C'est clair et concis.
Je suis d'accord, la comparaison côte à côte permet de comprendre facilement les principales différences entre les deux concepts.
J'apprécie que les exigences en matière de données pour le regroupement et la classification soient mises en évidence. C'est un facteur essentiel à prendre en compte dans les applications du monde réel.
L'explication détaillée de la classification, y compris les différents types de classificateurs, permet une compréhension complète de cette technique d'apprentissage automatique.
En effet, l’article fournit des informations précieuses sur les diverses applications des algorithmes de classification et leur importance dans le domaine de l’apprentissage automatique.
L'explication détaillée du regroupement et de la classification est intéressante, en particulier pour ceux qui sont nouveaux dans ces concepts.
Je ne pourrais pas être plus d'accord. Il fournit une base solide pour comprendre les principes fondamentaux de l’apprentissage automatique.
Absolument, la division entre les approches d’apprentissage non supervisé et supervisé est bien articulée dans cet article.
Les explications claires du clustering et de la classification sont très informatives et fournissent un aperçu complet de ces techniques d'apprentissage automatique.
Je ne pourrais pas être plus d'accord. L’article propose une analyse bien structurée et perspicace des deux concepts.
La distinction entre Hard Clustering et Soft Clustering est un aspect intrigant de l’article et ajoute de la profondeur à la discussion sur le clustering.
Absolument, c'est une considération importante lors de la mise en œuvre de méthodes de clustering dans différents contextes.
Je trouve cela fascinant aussi. Il montre la complexité et les nuances des techniques de clustering dans les applications du monde réel.
Les descriptions détaillées du clustering et de la classification, ainsi que de leurs algorithmes respectifs, offrent une compréhension complète de ces méthodes d'apprentissage automatique et de leur pertinence dans diverses applications.
Certainement. L'article transmet efficacement l'importance du regroupement et de la classification pour relever les défis réels de l'analyse des données dans différents domaines.
Le contexte historique fourni pour le regroupement est intéressant et ajoute de la profondeur à la discussion.
Certainement. Comprendre les origines de ces concepts permet de contextualiser leur importance dans l'analyse de données moderne et l'apprentissage automatique.
L'accent mis sur les approches d'apprentissage supervisé et l'importance de la valeur de sortie dans la classification est bien articulé et enrichit la compréhension de ces concepts.
Absolument. C'est un aspect crucial à prendre en compte lorsqu'on se penche sur la mise en œuvre pratique des algorithmes de classification.
Les applications mentionnées pour le clustering et la classification sont diverses et démontrent la pertinence de ces techniques dans divers domaines.
Absolument! Les exemples concrets sont cruciaux pour comprendre l’impact du regroupement et de la classification dans différents domaines.
Je suis complètement d'accord. Il est impressionnant de voir comment ces méthodes peuvent être appliquées dans des scénarios pratiques, de la ségrégation des clients au cloud computing.