
Nel mondo di oggi, l'apprendimento automatico è molto importante in quanto l'intelligenza artificiale è vista come parte integrante di esso. Lo studio degli algoritmi informatici utilizzando i dati è ciò che fa l'apprendimento automatico.
Raccolgono dati, noti anche come "dati di addestramento", per prevedere come eseguiranno le attività. L'apprendimento automatico viene utilizzato in una varietà di aree, come in medicina, filtraggio delle e-mail, ecc.
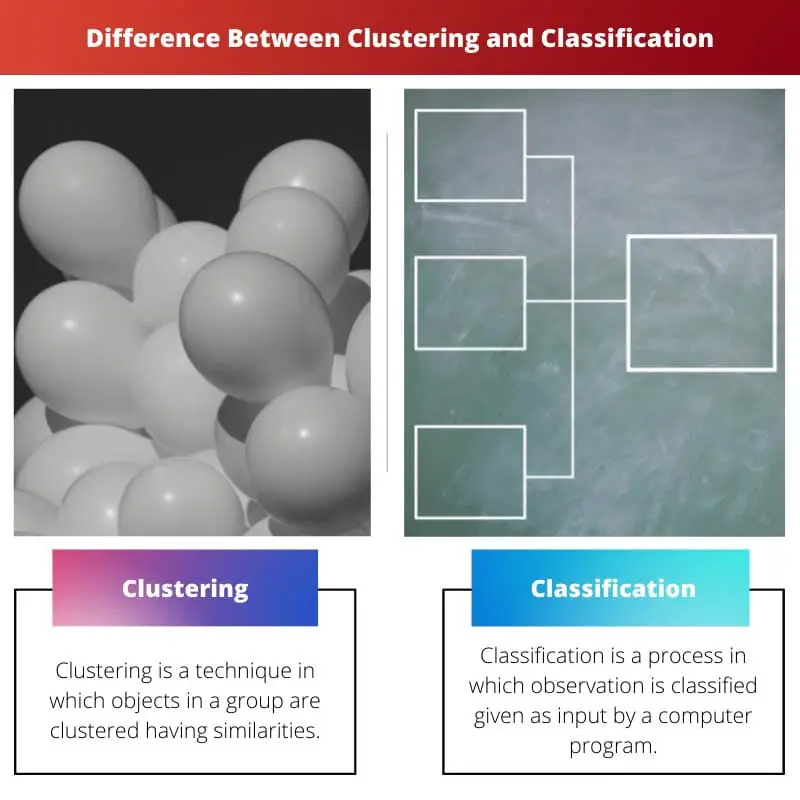
Il clustering e la classificazione utilizzano metodi statistici per la raccolta dei dati, in particolare nel campo dell'apprendimento automatico.
Punti chiave
- Il clustering è una tecnica utilizzata per raggruppare punti dati simili in base alle loro caratteristiche, mentre la classificazione categorizza i dati in classi predefinite in base alle loro caratteristiche.
- Il clustering è più utile quando non c'è una conoscenza preliminare dei dati e l'obiettivo è scoprire i modelli sottostanti. Allo stesso tempo, la classificazione è più adatta quando l'obiettivo è assegnare nuovi dati a categorie preesistenti.
- Vari algoritmi di clustering includono k-mean, gerarchico e DBSCAN, mentre vari algoritmi di classificazione includono alberi decisionali, regressione logistica e macchine vettoriali di supporto.
Clustering vs Classificazione
Il clustering raggruppa i punti dati in base alle somiglianze senza categorie predefinite, mentre la classificazione assegna i punti dati a classi predeterminate utilizzando l'apprendimento supervisionato. La differenza fondamentale risiede nell'approccio di apprendimento: il clustering utilizza tecniche non supervisionate e la classificazione si basa su metodi supervisionati.

Il clustering è anche chiamato analisi dei cluster nell'apprendimento automatico. È il processo in cui un oggetto viene raggruppato in modo tale che gli oggetti all'interno dei cluster abbiano proprietà simili, ma rispetto a un altro cluster, è molto diverso da esso.
Questa tecnica di clustering viene utilizzata nell'analisi statistica ed esplorativa dei dati in processi come l'analisi delle immagini, la compressione dei dati, il recupero delle informazioni, il riconoscimento dei modelli, la bioinformatica, la computer grafica e l'apprendimento automatico.
La classificazione è anche chiamata classificazione statistica nell'apprendimento automatico. È un processo in cui gli oggetti vengono classificati e inseriti in una serie di compartimenti categorizzati.
La classificazione viene effettuata su osservazioni quantificabili. Un algoritmo che incorpora la classificazione è noto come classificatore. La classificazione si basa su un processo in due fasi: le fasi di apprendimento e classificazione.
Tavola di comparazione
| Parametri di confronto | il clustering | Classificazione |
|---|---|---|
| Definizione | Il clustering è una tecnica in cui gli oggetti in un gruppo sono raggruppati con somiglianze. | La classificazione è un processo in cui l'osservazione è classificata come input da un programma per computer. |
| Dati | Il clustering non richiede dati di addestramento. | La classificazione richiede dati di addestramento. |
| Fase | Include un singolo stadio, cioè un raggruppamento. | Include due fasi: dati di addestramento e test. |
| Etichettatura | Si tratta di dati non etichettati. | Si occupa di dati etichettati e non etichettati nei suoi processi. |
| Obiettivo | Il suo obiettivo principale è svelare lo schema nascosto e le relazioni strette. | Il suo obiettivo è definire il gruppo a cui appartengono gli oggetti. |
Cos'è il clustering?
Il clustering fa parte dell'apprendimento automatico che raggruppa i dati in cluster con elevata somiglianza, ma i diversi cluster possono differire. È un metodo di apprendimento non supervisionato ed è molto comunemente usato per l'analisi dei dati statistici.
Esistono diversi tipi di algoritmi di clustering come K-means, DBSCAN, Fuzzy C-means, clustering gerarchico e gaussiano (EM).
Il clustering non richiede dati di addestramento. Rispetto alla classificazione, il clustering è meno complesso in quanto include solo il raggruppamento dei dati. Non assegna etichette a ogni gruppo come la classificazione.
Ha un processo a passaggio singolo noto come Raggruppamento. Il clustering può essere formulato come un problema di ottimizzazione multi-obiettivo incentrato su più problemi.
Il clustering è stato creato per la prima volta da Driver e Kroeber nel campo della antropologia nell'anno 1932. Poi fu introdotto nei vari campi da varie persone.
Cartell ha utilizzato il clustering popolare per la classificazione della teoria dei tratti nella psicologia della personalità nel 1943. Può essere approssimativamente distinto come Hard Clustering e Soft Clustering.
Ha diverse applicazioni, come ad esempio cliente segregazione, analisi dei social network, rilevamento delle tendenze dinamiche dei dati e ambienti di cloud computing.

Cos'è la classificazione?
La classificazione viene fondamentalmente utilizzata per il riconoscimento di modelli, in cui il valore di output viene assegnato al valore di input, proprio come il clustering. La classificazione è una tecnica utilizzata nel data mining ma utilizzata anche nell'apprendimento automatico.
In Machine Learning, l'output gioca un ruolo importante e nasce la necessità di Classificazione e Regressione. Entrambi sono algoritmi di apprendimento supervisionato, a differenza del clustering.
Quando l'output ha un valore discreto, viene considerato un problema di classificazione. Gli algoritmi di classificazione aiutano a prevedere l'output di un determinato dato quando viene fornito loro l'input.
Possono esserci vari tipi di classificazioni come la classificazione binaria, la classificazione multiclasse, ecc.
Diversi tipi di classificazione includono anche reti neurali, classificatori lineari: regressione logistica, classificatore Naïve Bayes: foresta casuale, alberi decisionali, più vicino prossimoe alberi potenziati.
Varie applicazioni dell'algoritmo di classificazione includono riconoscimento vocale, identificazione biometrica, riconoscimento della grafia, rilevamento di posta indesiderata, approvazione di prestiti bancari, classificazione di documenti, ecc. La classificazione richiede dati di addestramento e richiede dati predefiniti, a differenza del clustering. È un processo molto complesso. È il risultato di un apprendimento supervisionato. Si occupa di dati etichettati e non etichettati. Si tratta di due processi: formazione e test.
Principali differenze tra clustering e classificazione
- Il clustering è una tecnica in cui gli oggetti di gruppo sono raggruppati con somiglianze. È il risultato di un apprendimento supervisionato. La classificazione è un processo in cui l'osservazione è classificata come input da un programma per computer. È il risultato di un apprendimento senza supervisione.
- Il clustering non richiede dati di addestramento. La classificazione richiede dati di addestramento.
- Il clustering include il raggruppamento a fase singola. La classificazione comprende due fasi: formazione e test.
- Il clustering si occupa di dati senza etichetta. La classificazione si occupa di dati etichettati e non etichettati nei suoi processi.
- L'obiettivo principale del clustering è svelare il modello nascosto e le relazioni strette. L'obiettivo della classificazione è definire il gruppo a cui appartengono gli oggetti.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Ultimo aggiornamento: 18 giugno 2023

Sandeep Bhandari ha conseguito una laurea in ingegneria informatica presso la Thapar University (2006). Ha 20 anni di esperienza nel campo della tecnologia. Ha un vivo interesse in vari campi tecnici, inclusi i sistemi di database, le reti di computer e la programmazione. Puoi leggere di più su di lui sul suo pagina bio.






Queste informazioni sono molto utili per comprendere le principali differenze tra clustering e classificazione, nonché le loro applicazioni.
Assolutamente! È un'ottima panoramica delle tecniche di apprendimento automatico e dei loro usi pratici in diversi campi.
La tabella di confronto è particolarmente utile per comprendere i parametri di confronto tra clustering e classificazione. È chiaro e conciso.
Sono d'accordo, il confronto affiancato facilita la comprensione delle principali differenze tra i due concetti.
Apprezzo che i requisiti dei dati per il clustering e la classificazione siano evidenziati. È un fattore essenziale da considerare nelle applicazioni del mondo reale.
La spiegazione dettagliata della classificazione, inclusi i diversi tipi di classificatori, fornisce una comprensione completa di questa tecnica di apprendimento automatico.
In effetti, l’articolo fornisce preziosi spunti sulle varie applicazioni degli algoritmi di classificazione e sul loro significato nel campo dell’apprendimento automatico.
La spiegazione dettagliata del clustering e della classificazione è interessante, soprattutto per coloro che sono nuovi ai concetti.
Non potrei essere più d'accordo. Fornisce una solida base per comprendere i fondamenti dell'apprendimento automatico.
Assolutamente, la divisione tra approcci di apprendimento non supervisionato e supervisionato è ben articolata in questo articolo.
Le chiare spiegazioni del clustering e della classificazione sono altamente informative e forniscono una panoramica completa di queste tecniche di apprendimento automatico.
Non potrei essere più d'accordo. L’articolo offre un’analisi ben strutturata e approfondita di entrambi i concetti.
La distinzione tra Hard Clustering e Soft Clustering è un aspetto intrigante dell'articolo e aggiunge profondità alla discussione sul clustering.
Assolutamente, è una considerazione importante quando si implementano metodi di clustering in contesti diversi.
Lo trovo anch'io affascinante. Mostra la complessità e le sfumature delle tecniche di clustering nelle applicazioni del mondo reale.
Le descrizioni dettagliate del clustering e della classificazione, insieme ai rispettivi algoritmi, offrono una comprensione completa di questi metodi di apprendimento automatico e della loro rilevanza in varie applicazioni.
Decisamente. L'articolo trasmette in modo efficace l'importanza del clustering e della classificazione nell'affrontare le sfide dell'analisi dei dati del mondo reale in diversi domini.
Il contesto storico fornito per il clustering è interessante e aggiunge profondità alla discussione.
Decisamente. Comprendere le origini di questi concetti aiuta a contestualizzare il loro significato nella moderna analisi dei dati e nell'apprendimento automatico.
L'enfasi sugli approcci di apprendimento supervisionato e sul significato del valore di output nella classificazione è ben articolata e arricchisce la comprensione di questi concetti.
Assolutamente. È un aspetto cruciale da considerare quando si approfondisce l'implementazione pratica degli algoritmi di classificazione.
Le applicazioni menzionate sia per il clustering che per la classificazione sono diverse e dimostrano la rilevanza di queste tecniche in vari domini.
Assolutamente! Gli esempi del mondo reale sono cruciali per comprendere l'impatto del clustering e della classificazione in diversi campi.
Sono completamente d'accordo. È impressionante vedere come questi metodi possano essere applicati in scenari pratici, dalla segregazione dei clienti al cloud computing.