
Mūsdienu pasaulē mašīnmācība ir ļoti svarīga, jo mākslīgais intelekts tiek uzskatīts par tās neatņemamu sastāvdaļu. Datora algoritmu izpēte, izmantojot datus, ir mašīnmācīšanās.
Viņi vāc datus, kas pazīstami arī kā "apmācības dati", lai prognozētu, kā viņi veiks uzdevumus. Mašīnmācība tiek izmantota dažādās jomās, piemēram, medicīnā, e-pasta filtrēšanā utt.
Klasterizācija un klasifikācija izmanto statistikas metodes datu vākšanai, īpaši mašīnmācības jomā.
Atslēgas
- Klasterizācija ir paņēmiens, ko izmanto līdzīgu datu punktu grupēšanai, pamatojoties uz to īpašībām, savukārt klasifikācija iedala datus iepriekš noteiktās klasēs, pamatojoties uz to iezīmēm.
- Klasterizācija ir noderīgāka, ja nav iepriekšēju zināšanu par datiem, un mērķis ir atklāt pamatā esošos modeļus. Tajā pašā laikā klasifikācija ir piemērotāka, ja mērķis ir piešķirt jaunus datus jau esošām kategorijām.
- Dažādi klasterizācijas algoritmi ietver k-means, hierarhisko un DBSCAN, savukārt dažādi klasifikācijas algoritmi ietver lēmumu kokus, loģistikas regresiju un atbalsta vektoru mašīnas.
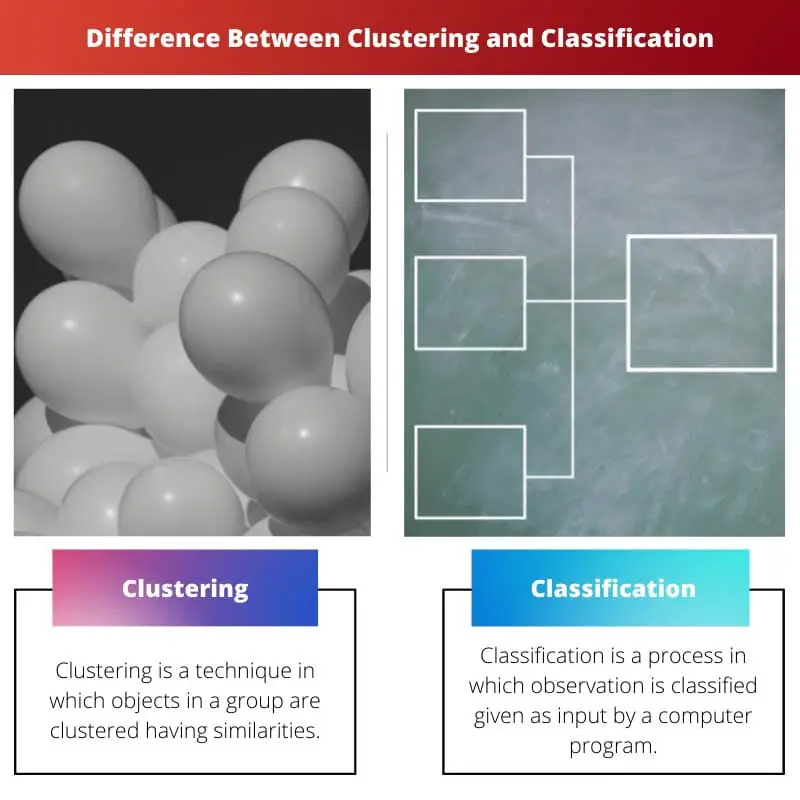
Klasterizācija pret klasifikāciju
Klasterizācija grupē datu punktus, pamatojoties uz līdzībām bez iepriekš definētām kategorijām, savukārt klasifikācija piešķir datu punktus iepriekš noteiktām klasēm, izmantojot uzraudzītu mācīšanos. Galvenā atšķirība ir mācīšanās pieejā: klasteru veidošanā tiek izmantotas neuzraudzītas metodes, un klasifikācija balstās uz uzraudzītām metodēm.

Klasterizāciju mašīnmācībā sauc arī par klasteru analīzi. Tas ir process, kurā objekts tiek grupēts tā, ka objektiem klasteros ir līdzīgas īpašības, bet, salīdzinot ar citu klasteru, tas tam ļoti atšķiras.
Šo klasterizācijas paņēmienu izmanto statistiskā un izpētes datu analīzē tādos procesos kā attēlu analīze, datu saspiešana, informācijas izguve, modeļu atpazīšana, bioinformātika, datorgrafika un mašīnmācīšanās.
Mašīnmācībā klasifikāciju sauc arī par statistisko klasifikāciju. Tas ir process, kurā objekti tiek klasificēti un ievietoti kategorizētu nodalījumu komplektā.
Klasifikācija tiek veikta, pamatojoties uz kvantitatīvi nosakāmiem novērojumiem. Algoritms, kas ietver klasifikāciju, ir pazīstams kā klasifikators. Klasifikācijas pamatā ir divpakāpju process: mācīšanās un klasifikācijas soļi.
Salīdzināšanas tabula
| Salīdzināšanas parametri | Klasterizācijas | Klasifikācija |
|---|---|---|
| Definīcija | Klasterizācija ir paņēmiens, kurā objekti grupā tiek grupēti ar līdzībām. | Klasifikācija ir process, kurā novērojumu klasificē kā datorprogrammas ievadi. |
| Datums | Klasterizācijai nav nepieciešami apmācības dati. | Klasifikācijai nepieciešami apmācības dati. |
| Fāze | Tas ietver vienpakāpes, ti, grupēšanu. | Tas ietver divus posmus: apmācības datus un testēšanu. |
| Marķēšana | Tas attiecas uz nemarķētiem datiem. | Tā savos procesos nodarbojas gan ar marķētiem, gan nemarķētiem datiem. |
| Mērķis | Tās galvenais mērķis ir atšķetināt slēpto modeli, kā arī šaurās attiecības. | Tās mērķis ir definēt grupu, kurai objekti pieder. |
Kas ir klasterēšana?
Klasterizācija ir daļa no mašīnmācīšanās, kas grupē datus klasteros ar augstu līdzību, taču dažādas kopas var atšķirties. Tā ir nekontrolētas mācīšanās metode, un to ļoti bieži izmanto statistikas datu analīzei.
Ir dažādi klasterizācijas algoritmu veidi, piemēram, K-means, DBSCAN, Fuzzy C-means, hierarhiskā klasterizācija un Gausa (EM).
Klasterizācijai nav nepieciešami apmācības dati. Salīdzinot ar klasifikāciju, klasterizācija ir mazāk sarežģīta, jo tā ietver tikai datu grupēšanu. Tas nedod etiķetes katrai grupai, piemēram, klasifikācijai.
Tam ir vienpakāpes process, kas pazīstams kā grupēšana. Klasterizāciju var formulēt kā vairāku mērķu optimizācijas problēmu, koncentrējoties uz vairākām problēmām.
Klasterizāciju vispirms izveidoja Driver un Kroeber jomā antropoloģija 1932. gadā. Tad ar to dažādās jomās iepazīstināja dažādas personas.
Kārtells 1943. gadā izmantoja populāro klasterizāciju iezīmju teorijas klasifikācijai personības psiholoģijā. To var aptuveni nošķirt kā cieto klasterizāciju un mīksto klasterizāciju.
Tam ir dažādas lietojumprogrammas, piemēram, klients segregācija, sociālo tīklu analīze, dinamisku datu tendenču noteikšana un mākoņdatošanas vides.

Kas ir klasifikācija?
Klasifikācija pamatā tiek izmantota modeļa atpazīšanai, kur ievades vērtībai tiek piešķirta izvades vērtība, tāpat kā klasterizācija. Klasifikācija ir metode, ko izmanto datu ieguvē, bet izmanto arī mašīnmācībā.
Mašīnmācībā izvadei ir svarīga loma, un rodas nepieciešamība pēc klasifikācijas un regresijas. Atšķirībā no klasterizācijas abi ir uzraudzīti mācību algoritmi.
Ja izvadei ir diskrēta vērtība, tā tiek uzskatīta par klasifikācijas problēmu. Klasifikācijas algoritmi palīdz paredzēt noteiktu datu izvadi, kad tiem tiek sniegta ievade.
Var būt dažāda veida klasifikācijas, piemēram, binārā klasifikācija, vairāku klašu klasifikācija utt.
Dažādi klasifikācijas veidi ietver arī neironu tīklus, lineāros klasifikatorus: loģistisko regresiju, naivā Bayes klasifikatoru: izlases mežu, lēmumu kokus, tuvākos. kaimiņš, un Boosted Trees.
Dažādi klasifikācijas algoritma lietojumi ietver runas atpazīšanu, biometrisko identifikāciju, rokraksta atpazīšanu, e-pasta surogātpasta noteikšanu, bankas aizdevuma apstiprināšanu, dokumentu klasifikāciju utt. Klasifikācijai ir nepieciešami apmācības dati, un atšķirībā no klasteru veidošanas tai ir nepieciešami iepriekš noteikti dati. Tas ir ļoti sarežģīts process. Tas ir uzraudzītas mācīšanās rezultāts. Tas attiecas gan uz iezīmētiem, gan nemarķētiem datiem. Tas ietver divus procesus: apmācību un testēšanu.
Galvenās atšķirības starp klasterizāciju un klasifikāciju
- Klasterizācija ir paņēmiens, kurā grupu objekti tiek grupēti ar līdzībām. Tas ir uzraudzītas mācīšanās rezultāts. Klasifikācija ir process, kurā novērojumu klasificē kā datorprogrammas ievadi. Tas ir nekontrolētas mācīšanās rezultāts.
- Klasterizācijai nav nepieciešami apmācības dati. Klasifikācijai nepieciešami apmācības dati.
- Klasterizācija ietver vienpakāpju, ti, grupēšanu. Klasifikācija ietver divus posmus: apmācību un testēšanu.
- Klasterizācija nodarbojas ar nemarķētiem datiem. Klasifikācija savos procesos attiecas gan uz marķētiem, gan nemarķētiem datiem.
- Klasterizācijas galvenais mērķis ir atšķetināt slēpto modeli, kā arī šaurās attiecības. Klasifikācijas mērķis ir definēt grupu, kurai objekti pieder.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Pēdējo reizi atjaunināts: 18. gada 2023. jūnijā

Sandeep Bhandari ir ieguvis inženierzinātņu bakalaura grādu datorzinātnēs Tapara universitātē (2006). Viņam ir 20 gadu pieredze tehnoloģiju jomā. Viņam ir liela interese par dažādām tehniskajām jomām, tostarp datu bāzu sistēmām, datortīkliem un programmēšanu. Vairāk par viņu varat lasīt viņa vietnē bio lapa.







Šī informācija ir ļoti noderīga, lai izprastu galvenās atšķirības starp klasterizāciju un klasifikāciju, kā arī to lietojumiem.
Pilnīgi noteikti! Tas ir lielisks pārskats par mašīnmācīšanās metodēm un to praktisko pielietojumu dažādās jomās.
Salīdzināšanas tabula ir īpaši noderīga, lai izprastu klasterizācijas un klasifikācijas salīdzināšanas parametrus. Tas ir skaidrs un kodolīgs.
Piekrītu, salīdzinājums līdzās ļauj viegli saprast galvenās atšķirības starp abiem jēdzieniem.
Es novērtēju, ka ir izceltas datu prasības klasterēšanai un klasifikācijai. Tas ir būtisks faktors, kas jāņem vērā reālās pasaules lietojumprogrammās.
Detalizēts klasifikācijas skaidrojums, tostarp dažādie klasifikatoru veidi, sniedz visaptverošu izpratni par šo mašīnmācīšanās paņēmienu.
Patiešām, raksts sniedz vērtīgu ieskatu par klasifikācijas algoritmu dažādajiem lietojumiem un to nozīmi mašīnmācības jomā.
Detalizēts klasterizācijas un klasifikācijas skaidrojums ir saprotams, jo īpaši tiem, kam šie jēdzieni ir jauni.
Es nevarēju vairāk piekrist. Tas nodrošina spēcīgu pamatu mašīnmācības pamatu izpratnei.
Šajā rakstā noteikti ir labi formulēts dalījums starp neuzraugāmām un uzraudzītām mācīšanās pieejām.
Skaidri klasterizācijas un klasifikācijas skaidrojumi ir ļoti informatīvi un sniedz visaptverošu pārskatu par šīm mašīnmācīšanās metodēm.
Es nevarēju vairāk piekrist. Raksts piedāvā labi strukturētu un ieskatu abu jēdzienu analīzi.
Atšķirība starp cieto klasterizāciju un mīksto klasterizāciju ir intriģējošs raksta aspekts un padziļina diskusiju par klasterizāciju.
Tas noteikti ir svarīgs apsvērums, ieviešot klasterizācijas metodes dažādos kontekstos.
Man arī tas šķiet aizraujoši. Tas parāda klasterizācijas metožu sarežģītību un nianses reālās pasaules lietojumprogrammās.
Detalizēti klasterizācijas un klasifikācijas apraksti, kā arī to attiecīgie algoritmi piedāvā visaptverošu izpratni par šīm mašīnmācīšanās metodēm un to nozīmi dažādās lietojumprogrammās.
Noteikti. Raksts efektīvi atspoguļo klasterizācijas un klasifikācijas nozīmi, risinot reālās pasaules datu analīzes problēmas dažādās jomās.
Klasterizācijas vēsturiskais konteksts ir interesants un padziļina diskusiju.
Noteikti. Izpratne par šo jēdzienu izcelsmi palīdz kontekstualizēt to nozīmi mūsdienu datu analīzē un mašīnmācībā.
Uzsvars uz pārraudzītām mācīšanās pieejām un iznākuma vērtības nozīmi klasifikācijā ir labi formulēts un bagātina šo jēdzienu izpratni.
Pilnīgi noteikti. Tas ir būtisks aspekts, kas jāņem vērā, iedziļinoties klasifikācijas algoritmu praktiskajā ieviešanā.
Gan klasteru veidošanai, gan klasifikācijai minētie lietojumi ir dažādi un parāda šo metožu nozīmi dažādās jomās.
Pilnīgi noteikti! Reālās pasaules piemēri ir ļoti svarīgi, lai izprastu klasterizācijas un klasifikācijas ietekmi dažādās jomās.
Pilnīgi piekrītu. Ir iespaidīgi redzēt, kā šīs metodes var pielietot praktiskos scenārijos, sākot no klientu segregācijas līdz mākoņdatniecībai.