
Gegevens zijn het belangrijkst voor bedrijfsorganisaties omdat ze deze opslaan en verwerken in databasebeheersystemen. Een databasebeheersysteem helpt gebruikers hun gegevens te bekijken zoals ze willen door de opslagdetails te verbergen.
Databasemodellen worden gebruikt om de gegevens naar de gebruikers te abstraheren. Hiërarchische en relationele databasemodellen worden het meest gebruikt bij het bouwen van databases.
Key Takeaways
- Hiërarchische databases gebruiken een boomachtige structuur en organiseren gegevens in ouder-kindrelaties.
- Relationele databases slaan gegevens op in tabellen met rijen en kolommen die met sleutels zijn verbonden.
- Relationele databases bieden meer flexibiliteit en gemak bij het opvragen in vergelijking met hiërarchische databases.
Hiërarchische database versus relationele database
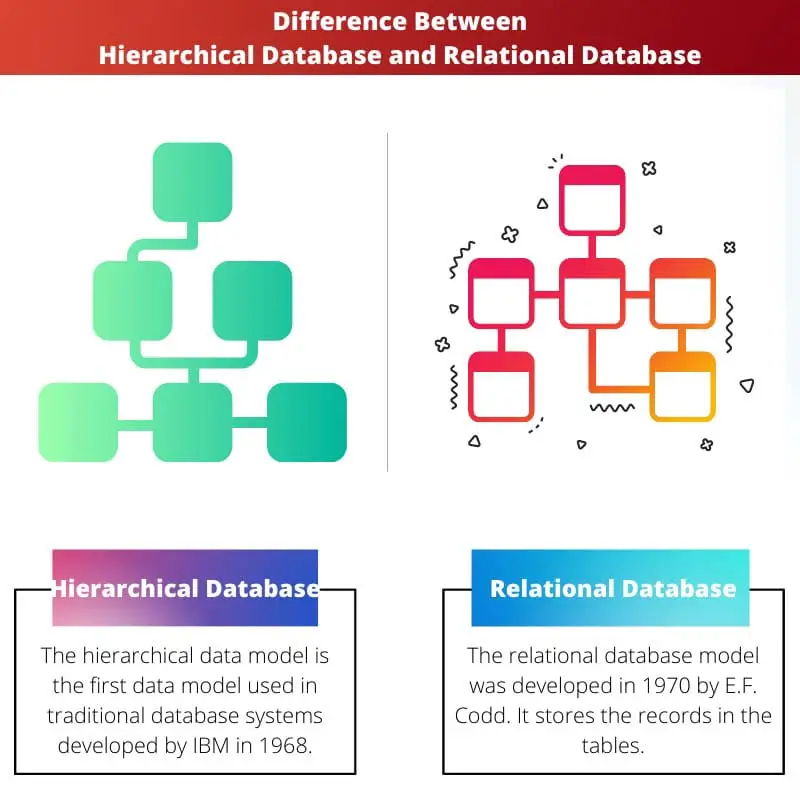
Een hiërarchische database slaat gegevens op in een boomachtige structuur met één bovenliggend record verbonden met meerdere onderliggende records en is geschikt voor het opslaan en ontsluiten van gegevens met een vaste structuur. Een relationele database slaat gegevens op in tabellen die gemeenschappelijke attributen of sleutels kunnen koppelen.

Een hiërarchische database is het databasesysteem van de eerste generatie dat wordt gebruikt in toepassingen om gegevens op te slaan en op te halen. Het wordt gebruikt in IBM mainframes zelfs vandaag.
Het is een eenvoudige databasestructuur maar niet geschikt voor het opslaan van complexe en grote datasets. Het ophalen van gegevens uit deze tabel is tijdrovend.
Aan de andere kant zijn relationele databasemodellen tweede generatie databasesystemen die de nadelen van hiërarchische databases overwinnen door de gegevens op te slaan in tabellen en views, en de databases met relaties te verbinden.
Het zorgt ervoor dat gegevens redundant zijn in de tabellen, waardoor het gemakkelijk is om ze op te halen, aan te passen en bij te werken.
Vergelijkingstabel
| Vergelijkingsparameters | Hiërarchische database | Relationele database |
| Ontwikkeld door | IBMin 1968 | EF Codd in 1970 |
| Generatie | Het is een gegevensmodel van de eerste generatie. | Het is een datamodel van de tweede generatie. |
| Structuur | Een boomstructuur met bovenliggende knooppunten en onderliggende knooppunten | De tabelvorm met rijen en kolommen |
| Relaties | Een-een, een-veel | Een-een, een-veel, veel-veel |
| Gegevens opvragen | De boom moet worden doorlopen van het hoofdknooppunt naar het gewenste knooppunt | SQL-querytaal gebruiken. |
Wat is een hiërarchische database?
Het hiërarchische datamodel is het eerste datamodel dat wordt gebruikt in traditionele databasesystemen ontwikkeld door IBM in 1968. Het is een model waarbij de gegevens worden opgeslagen in een ouder-kindmodel waarbij het kind slechts één ouder heeft.
Het vormt een boomachtige structuur waarbij onderliggende knooppunten de records zijn die via links zijn verbonden. Het eerste knooppunt in de boom wordt het hoofdknooppunt genoemd, dat geen bovenliggend knooppunt heeft.
Het bovenliggende knooppunt kan meerdere onderliggende knooppunten hebben, maar een onderliggend knooppunt moet alleen met het bovenliggende knooppunt zijn verbonden. Daarom voldoet het databasemodel aan een-een- en een-veel-relaties.
Het grootste voordeel van een hiërarchische database is dat toegang tot gegevens gemakkelijk en voorspelbaar is. Het ophalen en bijwerken zijn eenvoudig te optimaliseren.
Het grootste nadeel van de database is dat links niet kunnen worden gewijzigd omdat ze hard gecodeerd zijn. Als de database moet worden aangepast, moet de hele database opnieuw worden ontworpen.
De hiërarchische databases zijn eenvoudig maar flexibel. Het slaat redundante gegevens op, wat de complexiteit van het ophalen van de gegevens vergroot.
Aangezien de hiërarchische database in de applicatie moet worden gecodeerd, vereist elke wijziging in de database dat de ontwikkelaar de code van de applicatie wijzigt.
Hiërarchische databases worden nog steeds gebruikt in de IBM-mainframes, maar hebben niet de voorkeur voor moderne applicaties.
Wat is relationele database?
Het relationele databasemodel is in 1970 ontwikkeld door EF Codd. Het slaat de records op in de tabellen. De tabellen bestaan uit rijen en kolommen waarbij de rij entiteiten aangeeft en de kolom attributen van de records.
Tabellen zijn alleen gekoppeld aan relaties als ze gemeenschappelijke attributen delen. Relationele databases zijn gebruiksvriendelijk, programmeervriendelijk en hebben in bedrijfstakken de voorkeur boven hiërarchische databases.
Enkele van de relationele databasebeheersystemen zijn Oracle, DB2, MS-SQL Server en Informix.
Een relationele database is niet afhankelijk van applicaties en wijzigingen in de database hebben geen invloed op de programmering van de applicatie. Deze database is ook geschikt om eenvoudig complexe relaties tussen tabellen te definiëren.
In relationele databasesystemen wordt de logische structuur gescheiden opgeslagen van de fysieke structuur van de gegevens. Dit helpt om de structuren anders te beheren zonder elkaar te beïnvloeden.
Relationele databases volgen integriteitsregels om dubbele gegevens in de tabellen te elimineren. De SQL-querytaal wordt gebruikt om de gegevens consistent en nauwkeurig uit de database op te halen.
Relationele databases zorgen voor gemakkelijke toegang tot vereiste databases door consistentie te behouden. Het is ook gemakkelijk om eenvoudig een back-up te maken van gegevens, deze te importeren en te exporteren in geval van nood. Relationele databases voldoen ook aan een ACID-eigenschap.
Belangrijkste verschillen tussen hiërarchische database en relationele database
- De hiërarchische database moet binnen de applicatie worden gecodeerd, terwijl relationele databases onafhankelijk zijn van de applicatie.
- Hiërarchische database slaat gegevens op in de vorm van bovenliggende en onderliggende knooppunten die een boomstructuur vormen, terwijl een relationele database gegevens opslaat in de rijen en kolommen van een tabel.
- Een hiërarchische database implementeert alleen een-een- en een-op-veel-relaties, terwijl een relationele database ook veel-op-veel-relaties implementeert.
- De hele boom moet worden doorlopen om gegevens in een hiërarchische database op te halen, en SQL-querytaal wordt gebruikt in relationele databases om gegevens op te halen.
- De hiërarchische database is het databasesysteem van de eerste generatie en de relationele database is de database van de tweede generatie.
- https://www.google.co.in/books/edition/Introduction_to_Database_Systems/y7P9sa2MeGIC?hl=en&gbpv=0
- https://books.google.com/books?id=TFrbhHHxuXUC&printsec=frontcover&dq=beginning+mysql&hl=en&newbks=1&newbks_redir=1&sa=X&ved=2ahUKEwidpozo5O30AhWRTmwGHYJcChQQ6AF6BAgFEAI
Laatst bijgewerkt: 23 juni 2023

Sandeep Bhandari heeft een Bachelor of Engineering in Computers van Thapar University (2006). Hij heeft 20 jaar ervaring op het gebied van technologie. Hij heeft een grote interesse in verschillende technische gebieden, waaronder databasesystemen, computernetwerken en programmeren. Je kunt meer over hem lezen op zijn bio pagina.







Het artikel illustreert de voor- en nadelen van zowel hiërarchische als relationele databases en biedt een uitgebreid inzicht in hun verschillen.
De vergelijkingstabel biedt een duidelijk overzicht van de kenmerken en kenmerken van elk databasemodel, wat helpt bij het begrijpen van hun functionaliteiten.
Het artikel biedt een grondige uitleg van hiërarchische en relationele databases, waardoor de kennis op het gebied van databasebeheer wordt vergroot.
Informatief commentaar op de verschillende databasebeheersystemen en hun nut in bedrijfsorganisaties.
Het is intrigerend om het contrast te zien tussen hiërarchische en relationele databases, wat licht werpt op hun verschillende benaderingen van gegevensopslag.
Het is interessant om de historische ontwikkeling van deze databasesystemen te zien en hoe ze in moderne toepassingen worden gebruikt.
De databasevergelijkingen zijn inzichtelijk en bieden een waardevol inzicht in de fijne kneepjes van datamanagementsystemen.
Het is fascinerend om te leren over de vergelijking tussen hiërarchische en relationele databases en hoe ze gegevens op een andere manier opslaan en beheren.