
In der heutigen Welt ist maschinelles Lernen sehr wichtig, da künstliche Intelligenz als integraler Bestandteil davon angesehen wird. Das Studium von Computeralgorithmen mithilfe von Daten ist das, was maschinelles Lernen tut.
Sie sammeln Daten, auch „Trainingsdaten“ genannt, um vorherzusagen, wie sie die Aufgaben ausführen werden. Maschinelles Lernen wird in verschiedenen Bereichen eingesetzt, beispielsweise in der Medizin, beim Filtern von E-Mails usw.
Clustering und Klassifizierung nutzen statistische Methoden zur Datenerhebung, insbesondere im Bereich des maschinellen Lernens.
Key Take Away
- Clustering ist eine Technik, die verwendet wird, um ähnliche Datenpunkte basierend auf ihren Merkmalen zu gruppieren, während die Klassifizierung Daten basierend auf ihren Merkmalen in vordefinierte Klassen kategorisiert.
- Clustering ist nützlicher, wenn es keine Vorkenntnisse über die Daten gibt und das Ziel darin besteht, zugrunde liegende Muster zu entdecken. Gleichzeitig ist die Klassifizierung besser geeignet, wenn es darum geht, neue Daten bereits bestehenden Kategorien zuzuordnen.
- Verschiedene Clustering-Algorithmen umfassen k-means, hierarchisch und DBSCAN, während verschiedene Klassifizierungsalgorithmen Entscheidungsbäume, logistische Regression und Support-Vektor-Maschinen umfassen.
Clustering vs. Klassifizierung
Clustering gruppiert Datenpunkte basierend auf Ähnlichkeiten ohne vordefinierte Kategorien, während die Klassifizierung Datenpunkte mithilfe von überwachtem Lernen vorgegebenen Klassen zuordnet. Der Hauptunterschied liegt im Lernansatz: Beim Clustering kommen unbeaufsichtigte Techniken zum Einsatz, bei der Klassifizierung werden überwachte Methoden eingesetzt.

Clustering wird im maschinellen Lernen auch Clusteranalyse genannt. Dabei handelt es sich um den Prozess, bei dem ein Objekt so gruppiert wird, dass die Objekte innerhalb der Cluster ähnliche Eigenschaften haben, sich aber im Vergleich zu einem anderen Cluster stark unterscheiden.
Diese Clustering-Technik wird in der statistischen und explorativen Datenanalyse in Prozessen wie Bildanalyse, Datenkomprimierung, Informationsabruf, Mustererkennung, Bioinformatik, Computergrafik und maschinellem Lernen eingesetzt.
Die Klassifizierung wird beim maschinellen Lernen auch als statistische Klassifizierung bezeichnet. Dabei handelt es sich um einen Prozess, bei dem die Objekte klassifiziert und in eine Reihe kategorisierter Fächer eingeteilt werden.
Die Klassifizierung erfolgt anhand quantifizierbarer Beobachtungen. Ein Algorithmus, der die Klassifizierung berücksichtigt, wird als Klassifikator bezeichnet. Die Klassifizierung basiert auf einem zweistufigen Prozess: den Lern- und Klassifizierungsschritten.
Vergleichstabelle
| Vergleichsparameter | Clustering | Klassifikation |
|---|---|---|
| Definition | Clustering ist eine Technik, bei der Objekte in einer Gruppe mit Ähnlichkeiten geclustert werden. | Klassifizierung ist ein Prozess, bei dem Beobachtungen klassifiziert werden, die von einem Computerprogramm eingegeben werden. |
| Datum | Clustering erfordert keine Trainingsdaten. | Die Klassifizierung erfordert Trainingsdaten. |
| Phase | Es umfasst einstufige, dh Gruppierung. | Es umfasst zwei Schritte: Trainingsdaten und Tests. |
| Beschriftung | Es handelt sich um unbeschriftete Daten. | Es verarbeitet in seinen Prozessen sowohl gekennzeichnete als auch nicht gekennzeichnete Daten. |
| Ziel | Sein Hauptziel ist es, das verborgene Muster sowie enge Beziehungen aufzudecken. | Ihr Ziel ist es, die Gruppe zu definieren, zu der Objekte gehören. |
Was ist Clustering?
Clustering ist ein Teil des maschinellen Lernens, bei dem die Daten in Cluster mit hoher Ähnlichkeit gruppiert werden. Verschiedene Cluster können sich jedoch unterscheiden. Es handelt sich um eine Methode des unbeaufsichtigten Lernens, die sehr häufig zur statistischen Datenanalyse eingesetzt wird.
Es gibt verschiedene Arten von Clustering-Algorithmen wie K-Means, DBSCAN, Fuzzy C-Means, Hierarchical Clustering und Gaußian (EM).
Für das Clustering sind keine Trainingsdaten erforderlich. Im Vergleich zur Klassifizierung ist das Clustering weniger komplex, da es nur die Datengruppierung umfasst. Es werden nicht jeder Gruppe Etiketten wie bei der Klassifizierung zugewiesen.
Es handelt sich um einen einstufigen Prozess, der als Gruppierung bezeichnet wird. Clustering kann als ein Optimierungsproblem mit mehreren Zielen formuliert werden, das sich auf mehrere Probleme konzentriert.
Clustering wurde zuerst von Driver und Kroeber auf dem Gebiet der Anthropologie im Jahr 1932. Dann wurde es von verschiedenen Personen in die verschiedenen Bereiche eingeführt.
Cartell nutzte 1943 das populäre Clustering zur Klassifizierung der Merkmalstheorie in der Persönlichkeitspsychologie. Es kann grob in Hard Clustering und Soft Clustering unterschieden werden.
Es gibt verschiedene Anwendungen, wie z Kunde Segregation, Analyse sozialer Netzwerke, Erkennung dynamischer Datentrends und Cloud-Computing-Umgebungen.

Was ist Klassifizierung?
Die Klassifizierung wird im Wesentlichen zur Mustererkennung verwendet, wobei der Ausgabewert dem Eingabewert zugeordnet wird, genau wie beim Clustering. Die Klassifizierung ist eine Technik, die beim Data Mining, aber auch beim maschinellen Lernen verwendet wird.
Beim maschinellen Lernen spielt die Ausgabe eine wichtige Rolle, und es besteht die Notwendigkeit einer Klassifizierung und Regression. Im Gegensatz zum Clustering handelt es sich bei beiden um überwachte Lernalgorithmen.
Wenn die Ausgabe einen diskreten Wert hat, wird dies als Klassifizierungsproblem betrachtet. Klassifizierungsalgorithmen helfen dabei, die Ausgabe bestimmter Daten vorherzusagen, wenn ihnen Eingaben bereitgestellt werden.
Es kann verschiedene Arten von Klassifizierungen geben, z. B. binäre Klassifizierung, Klassifizierung mehrerer Klassen usw.
Zu den verschiedenen Arten der Klassifizierung gehören auch neuronale Netze, lineare Klassifikatoren: logistische Regression, naive Bayes-Klassifikatoren: Random Forest, Entscheidungsbäume, Nearest Nachbar, und Boosted Trees.
Zu den verschiedenen Anwendungen des Klassifizierungsalgorithmus gehören Spracherkennung, biometrische Identifizierung, Handschrifterkennung, E-Mail-Spam-Erkennung, Bankkreditgenehmigung, Dokumentenklassifizierung usw. Für die Klassifizierung sind Trainingsdaten und im Gegensatz zum Clustering vordefinierte Daten erforderlich. Es ist ein sehr komplexer Prozess. Es ist ein Ergebnis überwachten Lernens. Es handelt sich sowohl um gekennzeichnete als auch um unbeschriftete Daten. Es umfasst zwei Prozesse: Training und Testen.
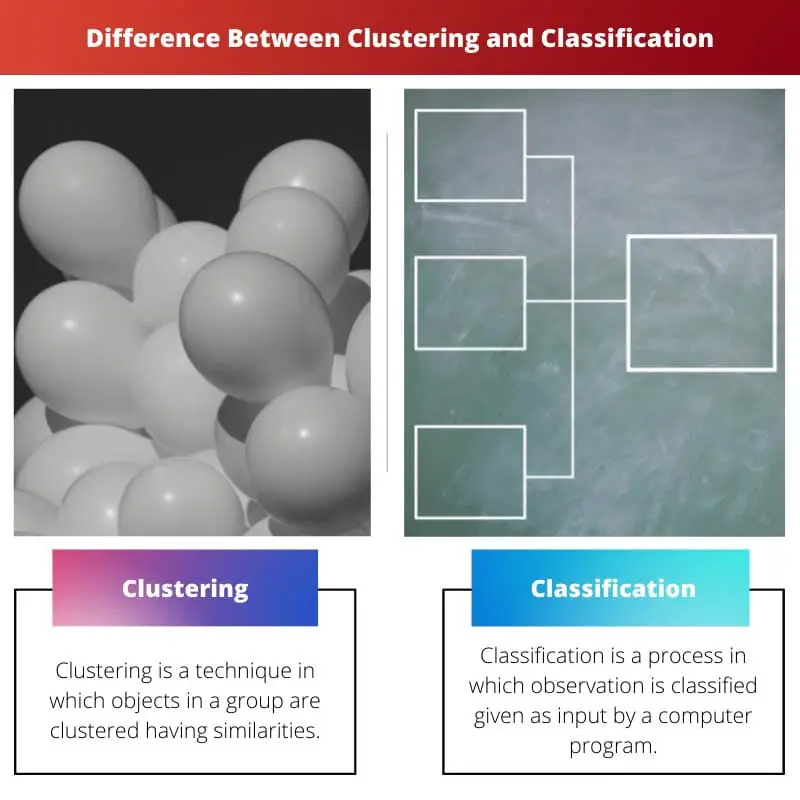
Hauptunterschiede zwischen Clustering und Klassifizierung
- Clustering ist eine Technik, bei der Gruppenobjekte mit Ähnlichkeiten gruppiert werden. Es ist ein Ergebnis überwachten Lernens. Klassifizierung ist ein Prozess, bei dem Beobachtungen klassifiziert werden, die als Eingaben eines Computerprogramms vorliegen. Es ist das Ergebnis unbeaufsichtigten Lernens.
- Clustering erfordert keine Trainingsdaten. Die Klassifizierung erfordert Trainingsdaten.
- Clustering umfasst einstufiges, also Gruppieren. Die Klassifizierung umfasst zwei Schritte: Schulung und Prüfung.
- Beim Clustering werden unbeschriftete Daten verarbeitet. Die Klassifizierung befasst sich in ihren Prozessen sowohl mit gekennzeichneten als auch mit nicht gekennzeichneten Daten.
- Das Hauptziel des Clusterings besteht darin, verborgene Muster und enge Zusammenhänge aufzudecken. Das Klassifizierungsziel besteht darin, die Gruppe zu definieren, zu der Objekte gehören.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Letzte Aktualisierung: 18. Juni 2023

Sandeep Bhandari hat einen Bachelor of Engineering in Computers von der Thapar University (2006). Er verfügt über 20 Jahre Erfahrung im Technologiebereich. Er interessiert sich sehr für verschiedene technische Bereiche, darunter Datenbanksysteme, Computernetzwerke und Programmierung. Sie können mehr über ihn auf seinem lesen Bio-Seite.






Diese Informationen sind sehr nützlich, um die wichtigsten Unterschiede zwischen Clustering und Klassifizierung sowie deren Anwendungen zu verstehen.
Absolut! Es bietet einen großartigen Überblick über Techniken des maschinellen Lernens und ihre praktische Anwendung in verschiedenen Bereichen.
Die Vergleichstabelle ist besonders hilfreich, um die Vergleichsparameter zwischen Clustering und Klassifizierung zu verstehen. Es ist klar und prägnant.
Ich stimme zu, der direkte Vergleich macht es einfach, die Hauptunterschiede zwischen den beiden Konzepten zu verstehen.
Ich weiß es zu schätzen, dass die Datenanforderungen für Clustering und Klassifizierung hervorgehoben werden. Dies ist ein wesentlicher Faktor, der bei realen Anwendungen berücksichtigt werden muss.
Die ausführliche Erläuterung der Klassifizierung, einschließlich der verschiedenen Arten von Klassifikatoren, vermittelt ein umfassendes Verständnis dieser maschinellen Lerntechnik.
Tatsächlich bietet der Artikel wertvolle Einblicke in die vielfältigen Anwendungen von Klassifizierungsalgorithmen und ihre Bedeutung im Bereich des maschinellen Lernens.
Die detaillierte Erläuterung von Clustering und Klassifizierung ist aufschlussreich, insbesondere für diejenigen, die mit den Konzepten noch nicht vertraut sind.
Ich kann nur zustimmen. Es bietet eine solide Grundlage für das Verständnis der Grundlagen des maschinellen Lernens.
Auf jeden Fall wird die Unterscheidung zwischen unbeaufsichtigten und überwachten Lernansätzen in diesem Artikel gut dargelegt.
Die klaren Erläuterungen zu Clustering und Klassifizierung sind äußerst aufschlussreich und bieten einen umfassenden Überblick über diese Techniken des maschinellen Lernens.
Ich kann nur zustimmen. Der Artikel bietet eine gut strukturierte und aufschlussreiche Analyse beider Konzepte.
Die Unterscheidung zwischen Hard Clustering und Soft Clustering ist ein interessanter Aspekt des Artikels und verleiht der Diskussion über Clustering Tiefe.
Dies ist auf jeden Fall ein wichtiger Gesichtspunkt bei der Implementierung von Clustering-Methoden in verschiedenen Kontexten.
Ich finde es auch faszinierend. Es zeigt die Komplexität und Nuancen von Clustering-Techniken in realen Anwendungen.
Die detaillierten Beschreibungen von Clustering und Klassifizierung zusammen mit ihren jeweiligen Algorithmen bieten ein umfassendes Verständnis dieser Methoden des maschinellen Lernens und ihrer Relevanz in verschiedenen Anwendungen.
Definitiv. Der Artikel vermittelt wirkungsvoll die Bedeutung von Clustering und Klassifizierung für die Bewältigung realer Datenanalyseherausforderungen in verschiedenen Bereichen.
Der für die Clusterbildung bereitgestellte historische Kontext ist interessant und verleiht der Diskussion Tiefe.
Definitiv. Das Verständnis der Ursprünge dieser Konzepte hilft, ihre Bedeutung für die moderne Datenanalyse und das maschinelle Lernen zu kontextualisieren.
Der Schwerpunkt auf überwachten Lernansätzen und der Bedeutung des Ausgabewerts bei der Klassifizierung ist gut formuliert und bereichert das Verständnis dieser Konzepte.
Absolut. Dies ist ein entscheidender Aspekt, der berücksichtigt werden muss, wenn man sich mit der praktischen Implementierung von Klassifizierungsalgorithmen befasst.
Die genannten Anwendungen für Clustering und Klassifizierung sind vielfältig und zeigen die Relevanz dieser Techniken in verschiedenen Bereichen.
Absolut! Die Beispiele aus der Praxis sind entscheidend für das Verständnis der Auswirkungen von Clustering und Klassifizierung in verschiedenen Bereichen.
Ich stimme vollkommen zu. Es ist beeindruckend zu sehen, wie diese Methoden in praktischen Szenarien angewendet werden können, von der Kundensegregation bis zum Cloud Computing.