
Trong thế giới ngày nay, học máy rất quan trọng vì trí tuệ nhân tạo được coi là một phần không thể thiếu trong đó. Việc nghiên cứu các thuật toán máy tính bằng cách sử dụng dữ liệu là công việc mà máy học thực hiện.
Họ thu thập dữ liệu, còn được gọi là 'dữ liệu đào tạo, để dự đoán cách họ sẽ thực hiện các nhiệm vụ. Học máy được sử dụng trong nhiều lĩnh vực, chẳng hạn như trong y học, lọc email, v.v.
Phân cụm và phân loại sử dụng các phương pháp thống kê để thu thập dữ liệu, đặc biệt là trong lĩnh vực học máy.
Chìa khóa chính
- Phân cụm là một kỹ thuật được sử dụng để nhóm các điểm dữ liệu tương tự dựa trên các đặc điểm của chúng, trong khi phân loại phân loại dữ liệu thành các lớp được xác định trước dựa trên các tính năng của chúng.
- Phân cụm hữu ích hơn khi không có kiến thức trước về dữ liệu và mục đích là khám phá các mẫu cơ bản. Đồng thời, phân loại phù hợp hơn khi mục tiêu là gán dữ liệu mới cho các danh mục có sẵn.
- Các thuật toán phân cụm khác nhau bao gồm phương tiện k, phân cấp và DBSCAN, trong khi các thuật toán phân loại khác nhau bao gồm cây quyết định, hồi quy logistic và máy vectơ hỗ trợ.
Phân cụm so với phân loại
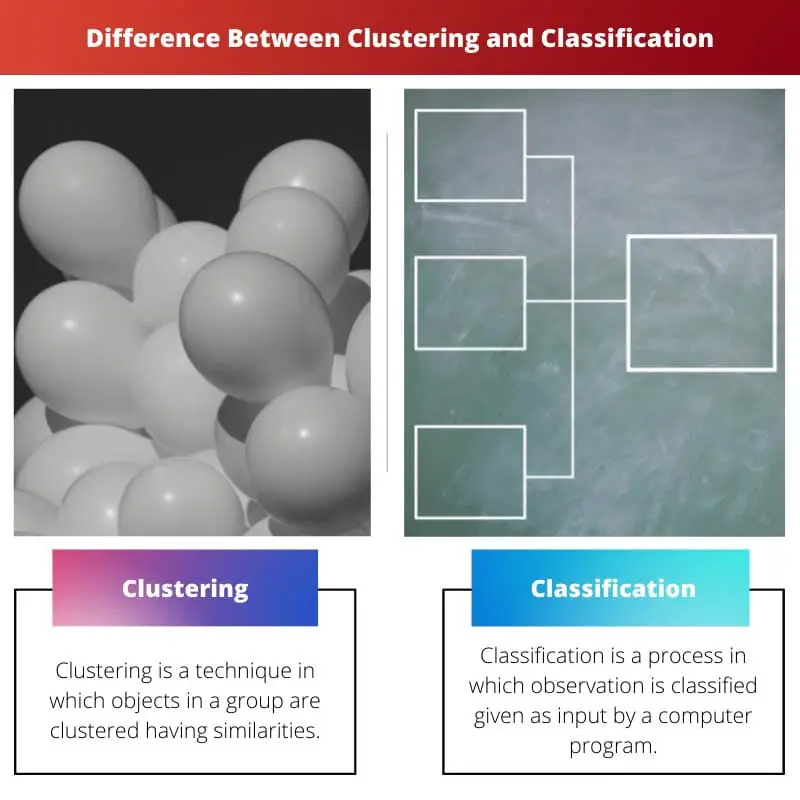
Phân cụm nhóm các điểm dữ liệu dựa trên những điểm tương đồng mà không có danh mục được xác định trước, trong khi phân loại chỉ định các điểm dữ liệu cho các lớp được xác định trước bằng cách sử dụng phương pháp học có giám sát. Sự khác biệt chính nằm ở phương pháp học tập: phân cụm sử dụng các kỹ thuật không được giám sát và phân loại dựa trên các phương pháp được giám sát.

Phân cụm còn được gọi là phân tích cụm trong học máy. Đó là quá trình trong đó một đối tượng được nhóm theo cách sao cho các đối tượng bên trong cụm có các thuộc tính tương tự nhau, nhưng khi so sánh với cụm khác, nó rất khác với cụm đó.
Kỹ thuật phân cụm này được sử dụng trong phân tích dữ liệu thống kê và khám phá trong các quy trình như phân tích hình ảnh, nén dữ liệu, truy xuất thông tin, nhận dạng mẫu, tin sinh học, đồ họa máy tính và học máy.
Phân loại còn được gọi là phân loại thống kê trong học máy. Đó là một quá trình trong đó các đối tượng được phân loại và đưa vào một tập hợp các ngăn được phân loại.
Phân loại được thực hiện trên các quan sát định lượng. Một thuật toán kết hợp phân loại được gọi là bộ phân loại. Việc phân loại dựa trên quy trình gồm hai bước: bước học và bước phân loại.
Bảng so sánh
| Các thông số so sánh | Clustering | phân loại |
|---|---|---|
| Định nghĩa | Phân cụm là một kỹ thuật trong đó các đối tượng trong một nhóm được phân cụm có những điểm tương đồng. | Phân loại là một quá trình trong đó quan sát được phân loại như đầu vào của một chương trình máy tính. |
| Ngày | Phân cụm không yêu cầu dữ liệu huấn luyện. | Phân loại yêu cầu dữ liệu đào tạo. |
| Giai đoạn | Nó bao gồm một giai đoạn, tức là, nhóm. | Nó bao gồm hai bước: đào tạo dữ liệu và thử nghiệm. |
| Ghi nhãn | Nó xử lý dữ liệu chưa được ghi nhãn. | Nó xử lý cả dữ liệu được gắn nhãn và không được gắn nhãn trong các quy trình của mình. |
| Mục tiêu | Mục tiêu chính của nó là làm sáng tỏ mô hình ẩn cũng như các mối quan hệ hẹp. | Mục tiêu của nó là xác định nhóm mà các đối tượng thuộc về. |
Phân cụm là gì?
Phân cụm là một phần của học máy giúp nhóm dữ liệu thành các cụm có độ tương đồng cao, nhưng các cụm khác nhau có thể khác nhau. Đây là một phương pháp học tập không giám sát và thường được sử dụng để phân tích dữ liệu thống kê.
Có nhiều loại thuật toán phân cụm khác nhau như K-means, DBSCAN, Fuzzy C-means, Hierarchical clustering và Gaussian (EM).
Phân cụm không yêu cầu dữ liệu huấn luyện. So với phân loại, phân cụm ít phức tạp hơn vì nó chỉ bao gồm việc phân nhóm dữ liệu. Nó không đưa ra nhãn cho mọi nhóm như phân loại.
Nó có một quy trình một bước được gọi là Nhóm. Phân cụm có thể được coi là một bài toán tối ưu hóa đa mục tiêu tập trung vào nhiều bài toán.
Phân cụm lần đầu tiên được tạo ra bởi Driver và Kroeber trong lĩnh vực nhân chủng học vào năm 1932. Sau đó, nó được nhiều người đưa vào các lĩnh vực khác nhau.
Cartell đã sử dụng phương pháp phân cụm phổ biến để phân loại lý thuyết đặc điểm trong tâm lý học nhân cách vào năm 1943. Nó có thể được phân biệt một cách đại khái là Phân cụm cứng và Phân cụm mềm.
Nó có các ứng dụng khác nhau, chẳng hạn như khách hàng tách biệt, phân tích mạng xã hội, phát hiện xu hướng dữ liệu động và môi trường điện toán đám mây.

Phân loại là gì?
Phân loại về cơ bản được sử dụng để nhận dạng mẫu, trong đó giá trị đầu ra được gán cho giá trị đầu vào, giống như phân cụm. Phân loại là một kỹ thuật được sử dụng trong khai thác dữ liệu nhưng cũng được sử dụng trong học máy.
Trong Machine Learning, đầu ra đóng một vai trò quan trọng và cần phải có Phân loại và Hồi quy. Cả hai đều là thuật toán học có giám sát, không giống như phân cụm.
Khi đầu ra có một giá trị kín đáo, thì nó được coi là một vấn đề phân loại. Các thuật toán phân loại giúp dự đoán đầu ra của một dữ liệu nhất định khi đầu vào được cung cấp cho chúng.
Có thể có nhiều loại phân loại khác nhau như phân loại nhị phân, phân loại đa lớp, v.v.
Các loại phân loại khác nhau cũng bao gồm Mạng thần kinh, Phân loại tuyến tính: Hồi quy logistic, Phân loại Naïve Bayes: Rừng ngẫu nhiên, Cây quyết định, Gần nhất Hàng xóm, và Cây tăng cường.
Các ứng dụng khác nhau của thuật toán phân loại bao gồm nhận dạng giọng nói, nhận dạng sinh trắc học, nhận dạng chữ viết tay, phát hiện thư rác, phê duyệt khoản vay ngân hàng, phân loại tài liệu, v.v. Phân loại yêu cầu dữ liệu đào tạo và nó yêu cầu dữ liệu được xác định trước, không giống như phân cụm. Đó là một quá trình rất phức tạp. Đó là kết quả của việc học có giám sát. Nó xử lý cả dữ liệu được gắn nhãn và không được gắn nhãn. Nó bao gồm hai quá trình: đào tạo và thử nghiệm.
Sự khác biệt chính giữa phân cụm và phân loại
- Phân cụm là một kỹ thuật trong đó các đối tượng nhóm được phân cụm với những điểm tương đồng. Đó là kết quả của việc học có giám sát. Phân loại là một quá trình trong đó quan sát được phân loại như đầu vào của một chương trình máy tính. Đó là kết quả của việc học không giám sát.
- Phân cụm không yêu cầu dữ liệu đào tạo. Phân loại yêu cầu dữ liệu đào tạo.
- Phân cụm bao gồm giai đoạn đơn, tức là phân nhóm. Việc phân loại bao gồm hai bước: đào tạo và kiểm tra.
- Phân cụm xử lý dữ liệu chưa được gắn nhãn. Phân loại xử lý cả dữ liệu được gắn nhãn và không được gắn nhãn trong các quy trình của nó.
- Mục tiêu chính của phân cụm là làm sáng tỏ mô hình ẩn cũng như các mối quan hệ hẹp. Mục tiêu phân loại là xác định nhóm mà các đối tượng thuộc về.
- https://books.google.com/books?hl=en&lr=&id=HbfsCgAAQBAJ&oi=fnd&pg=PR7&dq=clustering+and+classification+&ots=RVS-xBcH89&sig=6vliHhJ_PgtjPExTofGjDlvacaM
- https://onlinelibrary.wiley.com/doi/abs/10.1002/9780470027318.a5204.pub2
Cập nhật lần cuối: ngày 18 tháng 2023 năm XNUMX

Sandeep Bhandari có bằng Cử nhân Kỹ thuật Máy tính của Đại học Thapar (2006). Ông có 20 năm kinh nghiệm trong lĩnh vực công nghệ. Anh rất quan tâm đến các lĩnh vực kỹ thuật khác nhau, bao gồm hệ thống cơ sở dữ liệu, mạng máy tính và lập trình. Bạn có thể đọc thêm về anh ấy trên trang sinh học.






Thông tin này rất hữu ích để hiểu những khác biệt chính giữa phân cụm và phân loại, cũng như các ứng dụng của chúng.
Tuyệt đối! Đó là một cái nhìn tổng quan tuyệt vời về các kỹ thuật học máy và cách sử dụng thực tế của chúng trong các lĩnh vực khác nhau.
Bảng so sánh đặc biệt hữu ích để hiểu các tham số so sánh giữa phân cụm và phân loại. Nó rõ ràng và súc tích.
Tôi đồng ý, việc so sánh song song giúp bạn dễ dàng hiểu được sự khác biệt chính giữa hai khái niệm.
Tôi đánh giá cao rằng các yêu cầu về dữ liệu để phân cụm và phân loại đã được nêu rõ. Đó là một yếu tố thiết yếu cần xem xét trong các ứng dụng trong thế giới thực.
Giải thích chi tiết về phân loại, bao gồm các loại phân loại khác nhau, cung cấp sự hiểu biết toàn diện về kỹ thuật học máy này.
Thật vậy, bài viết cung cấp những hiểu biết sâu sắc có giá trị về các ứng dụng đa dạng của thuật toán phân loại và tầm quan trọng của chúng trong lĩnh vực học máy.
Giải thích chi tiết về phân cụm và phân loại rất sâu sắc, đặc biệt đối với những người mới làm quen với các khái niệm này.
Tôi không thể đồng ý nhiều hơn. Nó cung cấp nền tảng vững chắc để hiểu các nguyên tắc cơ bản của học máy.
Chắc chắn rồi, sự phân chia giữa các phương pháp học tập không giám sát và có giám sát đã được trình bày rõ ràng trong bài viết này.
Những giải thích rõ ràng về phân cụm và phân loại có tính thông tin cao và cung cấp cái nhìn tổng quan toàn diện về các kỹ thuật học máy này.
Tôi không thể đồng ý nhiều hơn. Bài viết cung cấp một phân tích có cấu trúc tốt và sâu sắc về cả hai khái niệm.
Sự khác biệt giữa Phân cụm cứng và Phân cụm mềm là một khía cạnh hấp dẫn của bài viết và bổ sung thêm chiều sâu cho cuộc thảo luận về phân cụm.
Chắc chắn đây là một điều quan trọng cần cân nhắc khi triển khai các phương pháp phân cụm trong các bối cảnh khác nhau.
Tôi thấy nó cũng hấp dẫn. Nó cho thấy sự phức tạp và các sắc thái của kỹ thuật phân cụm trong các ứng dụng trong thế giới thực.
Các mô tả chi tiết về phân cụm và phân loại, cùng với các thuật toán tương ứng, cung cấp sự hiểu biết toàn diện về các phương pháp học máy này và mức độ liên quan của chúng trong các ứng dụng khác nhau.
Chắc chắn. Bài viết truyền tải một cách hiệu quả tầm quan trọng của việc phân cụm và phân loại trong việc giải quyết các thách thức phân tích dữ liệu trong thế giới thực trên các lĩnh vực khác nhau.
Bối cảnh lịch sử được cung cấp cho việc phân cụm rất thú vị và bổ sung thêm chiều sâu cho cuộc thảo luận.
Chắc chắn. Hiểu được nguồn gốc của những khái niệm này giúp bối cảnh hóa tầm quan trọng của chúng trong phân tích dữ liệu hiện đại và học máy.
Sự nhấn mạnh vào các phương pháp học có giám sát và tầm quan trọng của giá trị đầu ra trong phân loại được trình bày rõ ràng và làm phong phú thêm sự hiểu biết về các khái niệm này.
Tuyệt đối. Đó là một khía cạnh quan trọng cần xem xét khi đi sâu vào việc triển khai thực tế các thuật toán phân loại.
Các ứng dụng được đề cập cho cả phân cụm và phân loại đều rất đa dạng và thể hiện sự liên quan của các kỹ thuật này trên các lĩnh vực khác nhau.
Tuyệt đối! Các ví dụ thực tế rất quan trọng để hiểu tác động của việc phân cụm và phân loại trong các lĩnh vực khác nhau.
Tôi hoàn toàn đồng ý. Thật ấn tượng khi thấy những phương pháp này có thể được áp dụng như thế nào trong các tình huống thực tế, từ phân biệt khách hàng đến điện toán đám mây.